

![]()
Die Meertalige Spraaktegnologieë-navorsingsgroep (Multilingual Speech Technologies, of MuST) het in 2010 by Noordwes-Universiteit (NWU) tot stand gekom, en is tans deel van die Fakulteit Ingenieurswese. Soos die naam suggereer, het die groep se navorsings- en ontwikkelingswerk van meet af aan op spraaktegnologie gefokus, en dan spesifiek in ’n meertalige konteks, en vir tale waarvoor daar min hulpbronne bestaan (soos wat die geval is met al Suid-Afrika se tale buiten Engels). Die benadering tot hierdie werk was tipies masjienleer en patroonherkenning; data word vir ’n rekenaarstelsel gevoer sodat dié daaruit kan leer, patrone identifiseer, en op grond daarvan afleidings kan maak wat op nuwe data toegepas kan word.

MuST bied elke jaar in Potchefstroom ’n inleidende kursus in diepleer vir nagraadse studente aan. Hierdie groepfoto is by 2020 s’n geneem. (Foto: verskaf)
MuST se werk strek oor verskeie areas van spraaktegnologie, waaronder masjienleer- en spraakprosesseringsnavorsing, asook die toepassing daarvan in tegnologieontwikkeling, en die integrasie daarvan in taalhulpbron- en eindgebruikerstoepassings.
Tegnologieontwikkeling en navorsing
Spraakherkenning en spraaksintese is van die bekendste tegnologieë in spraak. Die rekenaarmatige vermoë om te kan herken wat ’n persoon sê, vind nut in oneindig baie toepassings. Die mees voor die hand liggende is dikteerstelsels, en ander voorbeelde sluit in stelsels wat radio- en TV-uitsendings moniteer vir wat die media oor ’n besigheid berig, spraakgebaseerde soekfunksies soos wat Google op slimfone bied, en die slim assistente soos Siri wat gesproke vrae en instruksies kan herken deur spraakherkenningstegnologie.
Spraaksintese is die omgekeerde van spraakherkenning; Siri en die Google-assistent se antwoorde op vrae word gewoonlik in ’n teksformaat voorberei, en met spraaksintese word die teks dan na spraak omgeskakel (ook genoem teks-na-spraak) vir ’n oudio-antwoord. Hierdie tegnologieë kan ook in toepassings geïntegreer word om dienste en inligting toeganklik te maak vir mense wat nie kan skryf of lees nie, vanweë byvoorbeeld ongeletterdheid of gestremdhede.
In teenstelling met die goeie vooruitgang wat daar ten opsigte van spraaktegnologienavorsing en -ontwikkeling in die groot wêreldtale gemaak is, kon Suid-Afrika se inheemse tale as gevolg van ’n gebrek aan die nodige taalbronne en ander unieke uitdagings nie dieselfde ontwikkeling geniet nie. Wêreldwyd het ’n nisnavorsingsveld ontstaan waarin navorsers verskillende benaderings ondersoek om oplossings vir die eiesoortige probleme van tale met min hulpbronne te vind. Die Workshop on Spoken Language Technologies for Under-resourced Languages is een van die kongresse waar hierdie navorsers gereeld ontmoet om resultate te deel. MuST het ook hier ’n aantal aanbiedings gedoen oor spraakkorpusontwikkeling (spraakdataversamelings) en spraakherkenning, en was in 2012 medegasheer van die kongres toe dit in Suid-Afrika plaasgevind het.
Suid-Afrikaanse oplossings
Spesifieke vraagstukke waaraan MuST-navorsers in hierdie veld gewerk het, sluit in:
- Verbetering van prosodie om spraaksintese meer natuurlik te laat klink – iets wat in die vroeë dae van hierdie werk vir Suid-Afrikaanse tale ’n besondere uitdaging was. Toon is ook ’n belangrike kenmerk in die Afrikatale; woordbetekenis verander na gelang van toonhoogte en daarom is die akkurate herkenning en generering hiervan krities vir goeie spraakstelsels.
- Hantering van eiename en kodewisseling in spraaktegnologiestelsels. Suid-Afrika het plek- en mensename wat van verskillende tale afkomstig is, met die gevolg dat ’n spraakgebaseerde stelsel wat net vir ’n enkele taal opgelei is, nie optimaal kan funksioneer nie. Waar die groot wêreldtale se stelsels net op een taal hoef te fokus, moet stelsels in die Suid-Afrikaanse konteks tussen tale kan onderskei om effektief te wees. Hierdie stelsels moet byvoorbeeld die uitspraak van eiename in ’n veeltalige konteks kan voorspel, asook die interaksie tussen die spreker se taal en die oorsprong van die naam. MuST het binne die bestek van hierdie navorsing ’n aantal spraakkorpusse ontwerp en ontwikkel as hulpbronne om hierdie kwessies beter te verstaan.
- Innoverende toepassings vir die vinnige en effektiewe insameling, annotasie en analise van spraak as ’n oplossing vir die tekort aan korpusse vir die meeste plaaslike tale. Spraaktegnologiewerk is oor die algemeen baie afhanklik van die beskikbaarheid van data: In die masjienleerbenadering tot spraakverwerking word honderde ure se klanklêers en transkripsies in die betrokke taal benodig. Die hulpbronontwikkelingsinisiatiewe wat deur die Suid-Afrikaanse Departement van Kuns en Kultuur ondersteun is, was prysenswaardig, maar die projekbegrotings was nietig in vergelyking met internasionale korpusontwikkelingsprojeke, aangesien goeie gehalte korpusse moeisaam en tydrowend is om te versamel en te annoteer. Kreatiewe benaderings, soos slimfooninsamelingstoepassings met intydse kwaliteitsbeheer, was dus noodsaaklik om herbruikbare taalhulpbronne vir die Suid-Afrikaanse landstale te ontwikkel. MuST het saam met die Meraka Instituut van die Wetenskaplike en Nywerheidnavorsingsraad (WNNR) aan die NCHLT- en Lwazi-korpora gewerk om spraakkorpusse vir elk van die elf amptelike landstale te ontwikkel (Suid-Afrikaanse Engels word in die wêreld van spraaktegnologie as ’n heel ander taal as ander variasies van Engels beskou, en kan boonop nog verder onderverdeel word in Afrikaanse Engels, Indiërengels, ensovoorts, vandaar die nodigheid om korpora vir Engels ook te ontwikkel).
Eindgebruikerstelsels
Deur verskillende tegnologieë, soos dié waarna hierbo verwys word, te kombineer, kan baie nuttige eindgebruikershulpmiddele ontwikkel word. MuST se entrepreneuriese jonger navorsers het ’n aantal prototipes ontwikkel om die potensiaal van spraaktegnologie in die alledaagse en werksomgewing te demonstreer.
Die mees ambisieuse hiervan was ’n veeltalige spraaktranskripsieplatform. Die projek is deur die Departement van Kuns en Kultuur befonds en met die nasionale parlement se verslagdoeningseenheid as vennoot uitgevoer. Die doel van die projek was om spraak- en taaltegnologieë in ’n webgebaseerde stelsel saam te voeg om transkribeerders in hul taak te help. Die stelsel se funksionaliteit sluit outomatiese segmentering van oudiolêers volgens sprekeridentiteit, outomatiese transkripsie en speltoetsing in. Die stelsel kan die oudio en teks outomaties belyn sodat soektogte na spesifieke woorde in ’n oudiolêer uitgevoer kan word sonder om na die hele opname te moet luister. Verder is daar voorsiening gemaak vir ’n werkvloeibeheerstelsel vir werksverdeling, transkripsie en kwaliteitsbeheer. Die prototipe se bronkode is gratis beskikbaar gestel en in SADiLaR se katalogus opgeneem.
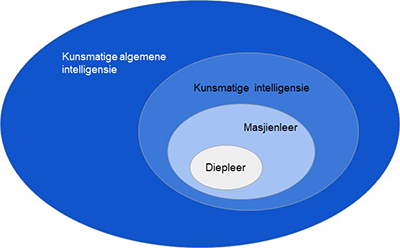
Diepleer: ’n herlewing in kunsmatige intelligensie
Binne die groep van masjienleertegnieke is daar ’n kategorie masjienleeralgoritmes wat as diepleer bekend staan. Daar is verskillende diepleerargitekture, waaronder diep neurale netwerke en konvolusienetwerke.
’n Diep neurale netwerk bestaan uit ’n aantal lae, elkeen met nodusse wat aan elke vorige en volgende nodus koppel. Elke laag onttrek toenemend hoërvlakkenmerke van die rou inset. Byvoorbeeld, in beeldherkenning sal die eerste lae die rante van voorwerpe identifiseer, en die daaropvolgende lae sal konsepte identifiseer, soos byvoorbeeld ’n syfer, gesig of kankergewas. Uiteindelik vind die netwerk die korrekte wiskundige manipulasie om die inset na ’n uitset om te skakel. Die neurale netwerk beskik dus oor die merkwaardige vermoë om uit die data wat vir hom gevoer word, te leer, en die kennis oor te dra na nuwe data wat hy nog nie voorheen gesien het nie.
Neurale netwerke as sulks is niks nuuts nie; daar word reeds vanaf die 1960’s daaroor gepubliseer en die onderwerp maak van tyd tot tyd sy verskyning, met tussenposes waar mense belangstelling verloor omdat die resultate nie na verwagting is nie. Dit is deels te wyte aan die onlangse verbetering in hardeware en rekenaarverwerkingskrag dat die potensiaal van neurale netwerke begin ontsluit word.
Voorbeeld van ’n neurale netwerk (Foto: verskaf)
Neurale netwerke het inderdaad in die laaste paar jaar wêreldwyd ’n herlewing in navorsing en ontwikkeling op die gebied van kunsmatige intelligensie veroorsaak – van rekenaars wat mense in bordspeletjies wen en motors wat self bestuur, tot spraak- en taaltegnologie. 2019 was, om die waarheid te sê, ’n grensverskuiwende jaar vir natuurliketaalprosessering. Daar is byvoorbeeld stelsels ontwikkel wat vrae vanuit ’n stuk teks kan beantwoord met veel beter uitkomste as enige voorafgaande oplossings (hoewel nog baie ver van menslike vermoëns in hierdie verband).
Nuwe navorsingsfokus
In onlangse jare het MuST se belangstelling begin skuif vanaf spraaktegnologie as sulks na die teorie agter een van die nuwe benaderings tot spraaktegnologie: diep neurale netwerke. Ten spyte daarvan dat diep neurale netwerke ’n sleutelkomponent in ontwikkelingswerk binne die breë veld van kunsmatige intelligensie is (insluitend spraak- en taaltegnologie), bly dit onduidelik waarom hulle so suksesvol werk.
Daar is ’n verskeidenheid instrumente en dienste op die internet beskikbaar, wat die bekostigbaarheid en toeganklikheid van netwerkafrigting toenemend verbeter, veral vir klein groepe en selfs individue tuis. Google en Amazon, onder andere, bied platforms aan waar netwerke afgerig kan word. Wat binne hierdie afrigproses gebeur, is egter ’n raaisel; niemand verstaan wat tussen die inset- en uitsetlae van die netwerk gebeur nie, en moet gewoon die uitset aanvaar, of blindelings hier en daar verstellings maak, die netwerk weer afrig en hoop dat die uitset sal verbeter.
Sedert 2018 fokus MuST se werk daarop om hierdie raaisel uit te pluis, hoofsaaklik op ’n teoretiese vlak, om die beginsels van veralgemening in diepleertegnieke te verstaan. Saam met ’n vinnig-groeiende internasionale gemeenskap van wetenskaplikes soek die groep na antwoorde op die vrae rondom hierdie netwerke. ’n Beter verstaan van diep neurale netwerke sal die metode van leer en probeer in netwerkafrigting verander na een waar verstellings doelgerig en afgemete geïmplementeer kan word om verrigting te verbeter. Deurbrake op hierdie vlak kan die grenslyne in wat tans in kunsmatige intelligensie moontlik is, beduidend verander en produkte lewer wat tans nog net in drome en films bestaan.
Hierdie artikel is deel van die miniseminaar "Die Vierde Nywerheidsrevolusie" wat in samewerking met die SA Akademie vir Wetenskap en Kuns, die ATKV en Solidariteit Navorsingsinstituut aangebied word. Lees al die bydraes hier: