


Agtergrondfoto: Gerd Altmann | Pixabay
Die Stellenbosch Institute for Advanced Study (Stias) het onlangs verskeie rolspelers byeengebring. Die geleentheid op 1 Julie 2021 het plaasgevind onder die vaandel “Outomatiese spraakherkenning in Afrikaans”.
Wat is outomatiese spraakherkenning?
Die eenvoudigste manier om spraakherkenning te verduidelik, sou wees om te sê dat ’n mens met ’n rekenaar kan gesels en dat die rekenaar dan die nodige aksie sal neem volgens die gesprek, of dat die rekenaar sinvolle, gesproke instruksies aan ’n mens kan gee.
Ure en ure se masjienleer
Maar hoe weet ’n rekenaar wat ons sê?
Neem ’n eenvoudige opdrag: Oor driehonderd meter, draai regs.
Die klink so: oordriehonderdmeter draairegs en lyk dalk so as ons die klankgolwe analiseer:
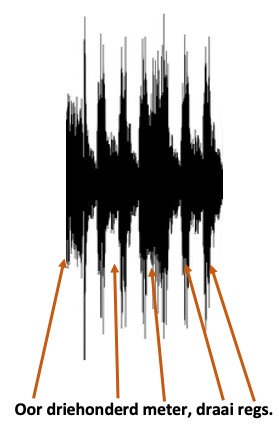
Nota bene, hierdie golwe is ter illustrasie en is nie akkuraat nie.
Mense weet instinktief wat om met daardie boodskap te doen.
- As jy die boodskap vir ’n Afrikaanssprekende tikster sou gee, sou sy so kon tik: Oor driehonderd meter, draai regs.
- As jy die opdrag vir ’n Afrikaanssprekende motorbestuurder sou gee, sou sy akkuraat in die korrekte straat afdraai.
’n Rekenaar moet uiteindelik ook die boodskap so kan verstaan.
Die vraag is: Hoe leer ’n rekenaar taal aan?
Die beste manier om vir ’n rekenaar taal te leer, is om geskrewe tekste te laat voorlees.
Dus, op ’n baie eenvoudige skaal, sal meer as een persoon byvoorbeeld lees: Oor driehonderd meter, draai regs. Daardie teks en die opnames sal dan aan die rekenaar gebied word.
Die rekenaar hoor ’n aanhoudende stroom klankgolwe oordriehonderdmeter draairegs en moet nou hierdie klankgolwe analiseer en in kode omskep.

Een enkele klankgreep in daardie golf bestaan uit ritse en ritse kode – iets soos 1.423/0.981/0.732 ... en nog baie, baie meer. (Kodes hier dien ter illustrasie, en is nie akkuraat nie.)
Die rekenaar moet nou al hierdie ritse en ritse kode in volgorde plaas.
Draai regs bestaan uit stringe kode wat hierdie klanke moet herken:
- d
- r
- aa
- i
- r
- e
- g
- s
Die klanke moet dan gepas word teen woorde in die databasis ...
- d
- r
- aa
- i > draai
- r
- e
- g
- s >regs
Sou die rekenaar die klankgolwe dan korrek interpreteer en kodeer, sou dit die opdrag aktiveer om draai regs te tik, of dit sou aksies in ’n motor kon aktiveer om by ’n volgende straat regs te draai deur met die satellietnavigasie en die sensors in die motor te kommunikeer.
Spraakvariante
Dink egter mooi: Ek praat anders as my sussie, my sussie praat anders as my ouma, en dan het ons nog nie eens van my neef gepraat wat op die Weskus grootgeword het en sal sê Dgaai gegs nie.
Aksente en spraakvariante maak dit vir mense moeilik om mekaar te verstaan, en maak dit vir rekenaars veral moeilik om mense te verstaan.
Dit is waar herhaling én masjienleer inkom.
As talle mense dieselfde geskrewe teks vir ’n rekenaar voorlees, sal die rekenaar uiteindelik beter word om verskillende weergawes van dieselfde woord te herken.
Kunsmatige intelligensie kan dit selfs moontlik maak om my neef se Weskus-aksent te herken in ’n ánder spreker van die Weskus af en sodoende die klanklêers van my neef te gebruik om hierdie persoon se instruksies te probeer interpreteer.
Dit is egter duisende ure se voorlees wat nodig is vir masjiene om outonoom woorde te leer verstaan.
Dit is hoekom dit so duur is om hierdie stukke sagteware te bou.
Om gesprekke te transkribeer
Dit is een ding om ’n eenvoudige sin aan ’n rekenaar te leer. Maar kan ’n rekenaar inluister op ’n gesprek tussen ’n klomp mense en daarmee iets doen?
Dink daaraan: Drie verskillende mense gesels. Hulle almal praat anders. Al die aksente verskil dalk. Soms verwissel hulle van taal, soos ’n mens mos maar your languages soms mix in ’n gesprek.
Die rekenaar moet nou:
- Elke individu se woorde kodeer.
- Die uitings verkieslik so transkribeer dat dit leesbaar is – leestekens help dus.
- Elke individu se aksent verstaan, en elkeen se spreekbeurt aandui.
- Tussen verskillende tale kan onderskei.
Hoe doen die slim mense dit?
Hulle neem gesprekke tussen mense op en laat daardie gesprekke transkribeer, dan voer hulle die transkripsies van die gesprekke saam met die klank aan die rekenaar. Nog ure en ure se menslike sweet, dus.
Vir ’n deeglike analise van hierdie onderwerp, lees die seminaar wat vroeër reeds op LitNet gepubliseer is.
Waarvoor gebruik ons hierdie toepassings?
Selfoongebruikers weet dat sommige fone reeds op ’n baie beperkte manier opdragte kan uitvoer, maar die toepassing van stem- en spraakherkenning gaan veel verder as ’n selfoon wat soms ’n eenvoudige opdrag kan regkry. Siri en haar maats sal ons eendag kan help, maar intussen word veel belangriker toepassings ontwikkel. Hier is enkele voorbeelde:
- Dikteerprogramme: ’n Persoon praat en die rekenaar tik dit wat die persoon sê. Hierdie toepassing is veral belangrik in onderwyskringe, maar ook in die regs-mediese beroepe waar notas geneem moet word wat akkuraat is. (Sien meer hier onder.)
- Onderskrifte by video’s en lesings: Vir hardhorende mense is dit noodsaaklik om te kan lees wat mense op ’n skerm sê. Dit is reeds vir rekenaars moontlik om hierdie onderskrifte in sommige tale outomaties by te sit.
- Mediamonitering: Groot maatskappy betaal ander maatskappye om hulle te laat weet wanneer daar oor hul handelsmerk gepraat word. Gestel maatskappy XYZ wil weet wat oor sy produkte gesê word, dan sal websnuffelaars hom laat weet die oomblik wanneer XYZ in die media genoem word. Dit is deesdae maklik op die internet – dit gebeur reeds outomaties – maar tot baie onlangs moes mense voor radio’s of TV-stelle sit en luister om te hoor wanneer XYZ op die lug ter sprake kom. Spraakherkenning maak dit al hoe makliker vir rekenaars om nou radio- en TV-stasies te monitor en akkurate tellings te hou van die kere dat en die konteks waarin die handelsmerk genoem word.
- Stembeheerde en stemgedrewe verspreidingsentrums: Dink aan enorme pakstore waar miljoene items goedere geberg word. Rekenaars kan deesdae aan pakkers sê wat om van die rak af te haal, en selfs waar om die produk te gaan kry. Die inkopie, wat as teks gestoor is, word dus aan daardie pakker as ’n stemboodskap gegee, met instruksies waar om dit te kry en hoeveel van elke item benodig word.
- Kwaliteitbeheer in inbelsentrums: As jy ooit ’n kontrak oor die foon probeer sluit het, sal jy weet die arme persoon moet deur lyste goed lees ... Rekenaars volg deesdae elke oproep om seker te maak dat elke item voorgelees is.
Spraak na teks: Dikteerprogramme gee hoop
’n Rekenaar wat na jou spraak kan luister en dan tik wat jy sê, maak ’n enorme verskil aan die lewe van talle mense, veral leerders, wat ’n leer- en leesuitdaging het.
Die feit dat jy hier lees, beteken waarskynlik dat jy nie sukkel om te lees nie. Daar is egter miljoene mense in die wêreld wat nie so gelukkig is nie.
Probeer hierdie stukkie baie eenvoudige Afrikaans vinnig en vlot lees – dit het onlangs op LitNet verskyn.

Sukkel jy? Dan begin jy dalk verstaan hoe dit voel vir iemand wat ’n leesuitdaging het. Woorde en sinne “gedra” hulle net glad nie, en baie mense dink ’n persoon wat met ’n eenvoudige teks sukkel, is dom. Glad nie. Vir hulle lyk alle teks soortgelyk aan die teks in die voorbeeld hier bo.
Tydens die Stias-gesprek is voorbeelde gegee van kinders met disleksie wat hoegenaamd nie ’n sin kan skryf nie, maar hulle kan hulle baie goeie idees verbaal uitdruk. As daardie vertelling deur ’n rekenaar neergeskryf sou kon word, kan daardie leerder met ander kinders meeding.
Dit gebeur reeds in talle skole en laat kinders blom.
Daar is selfs nagraadse studente wat steeds hierdie soort hulpmiddels gebruik, en sonder sodanige hulp sou hulle sukkel om te presteer.
In Engels is daar reeds ’n aantal spraakherkenningsisteme wat taamlik goed werk. In Suid-Afrika word daar nou baie hard daaraan gewerk om Afrikaans ook op hierdie vlak te bring.
Maar dink ’n bietjie wat alles in so ’n program moet ingaan:
- Dit moet in die eerste plek die woorde verstaan, die klanke dan in kode omskep en die woorde spel.
- Dan, die volgende uitdaging: Hoe weet die rekenaar waar om punte, kommas en paragrawe te sit?
Leestekens en spraakherkenning
Wanneer daar vir ’n rekenaar voorgelees word, kan die voorleser kodes soos punt, komma en nuwe paragraaf gebruik, maar die rekenaar moet dit kan verstaan. Anders sal so iets die gevolg wees: Die rekenaar moet dit kan verstaan komma anders gaan so iets gebeur punt dit kan natuurlik reggestel word komma maar dit neem ekstra tyd punt.
In Engels is daar programme wat redelik intuïtief sinne kan opbreek, en talle Engelse spraakherkenningsprogramme kan al iets soos they sat down comma had breakfast and walked on full stop korrek tik, hoofletter en al: They sat down, had breakfast and walked on.
Baie, baie masjienleertyd gaan egter daarin om ’n rekenaar dit te laat verstaan, en in Suid-Afrika is daar tans maatskappye wat daaraan werk om Afrikaanse stelsels ewe goed te laat werk.
Teks na spraak
As jy al ooit ’n GPS gebruik het, sal jy weet dat GPS’e deesdae taamlik akkurate Engelse stemboodskappe kan gee.
Maar daar is ander redes waarom ’n rekenaar teks moet kan voorlees.
- Dink aan die talle koerante wat jy deesdae aanlyn kan luister terwyl jy bestuur of handwerk doen.
- Dink aan gesiggestremde mense, hoe dit hulle help om enige teks te kan lees.
- Dink dan ook aan leerders met ’n ernstige leer- en leesprobleem.
Hier is ’n video oor die werk wat die WNNR tans doen. Let veral op na twee dinge:
- Die manier waarop verskillende tale in een sin korrek uitgespreek word (sien dan ook die seminaar deur Fede de Wet en Thomas Niesler).
- Die manier waarop woorde kan ophelder soos wat die rekenaar die teks lees.
Laasgenoemde – die feit dat woorde ophelder – maak ’n enorme verskil aan iemand wat ’n leesprobleem, soos disleksie, of erge aandagafleibaarheid het.
Plaas jouself vir ’n oomblik weer in die skoene van iemand wat sukkel om te lees. Hier is daardie deurmekaar teks van vroeër weer. Dié keer is ’n beter skriftipe gekies.

Volg die pyltjies en die getalle, en luister na die voorlesing.
Dit is steeds moeilik om te lees. Tegnologie maak dit nie maklik vir mense met disleksie nie, maar daar is ten minste nou die vermoë om te begin verstaan.
’n Veel meer tegniese analise hiervan is beskikbaar. In dié meer tegniese analise word hierdie e-leser bekendgestel.

Tydens die Stias-werkswinkel is hierdie diagram soos volg verduidelik:
- Converter: Die e-leser sal outomaties dokumente uit Word en PDF na ePub3 omskakel.
- Augmenter: Voeg menslike, of sintetiese, stem by en belyn die teks met die klank.
- Reader: Lees die teks, waarvan woorde ophelder soos wat dit voorgelees word, verander die skriftipe, pas die leesspoed aan, en help die leser om tussen woorde, paragrawe, afdelings en hoofstukke te navigeer.
Ter afsluiting
Die gesprek is aangebied deur die Stellenbosch Universiteit, VivA en Saigen.
- Febe de Wet, van die Stellenbosch Universiteit, het die reëlings getref en die dag bestuur.
- Madelein Kruger en Leanie Joubert, arbeidsterapeute van die Langerugskool, se gesprek was getiteld “Hoe om die kurrikulum toeganklik te maak vir leerders met leerhindernisse” en Chrismarie Whitehead, van Curro Uitzicht, het gesels oor “Tegnologiese hulpmiddels vir leerders met leerhindernisse”.
- Ilana Wilken, van die WNNR het verduidelik hoe hulle e-boekprojek toeganklik gemaak word vir verskillende taalgemeenskappe.
- Rudi le Roux, Stellenbosch Universiteit, se praatjie was oor “Ondersteunende tegnologie vir studente met spesiale leerbehoeftes”.
- Roné Wieringa, van VivA, het produkevaluering van verskillende dikteerstelsels in Afrikaans gedoen.
- Marlie Coetzee, ook van VivA, het die bevindinge van hulle marknavorsing oor spraaktegnologie gedeel.
- “Spraaktegnologie en toepassings daarvan in die Suid-Afrikaanse konteks” was die titel van Charl van Heerden, betrokke by Saigen, se praatjie.
- Juan Bornman, verbonde aan die Universiteit van Pretoria, het gesels oor “Die rol van spraaktegnologie in ’n taalsteekproefanalise”.
In verskeie fiksietekste kom gevorderde rekenaars voor wat gesprekke met mense kan voer, net soos twee mense sou kon. Sulke gesprekke is reeds op ’n baie beperkte skaal moontlik, maar intussen word outomatiese spraakherkenning al hoe beter, ook in Afrikaans. In Willem Anker se Skepsel word die pratende huis geprogrammeer om korrek in Afrikaans te kommunikeer deur middel van ure en ure se kassette wat aan haar gespeel word. In-Grid, die hoofraamrekenaar as karakter in Isa Konrad se Toekomsmens, en Agnes, haar voorganger, word ook geskep uit menslike data wat in hulle ingevoer word.
Die gesprek van 1 Julie toon hoe toekomsfiksie vandag in die werklikheid reeds deur ons land se wetenskaplikes moontlik gemaak word. Hulle doen dit vir Afrikaans, en ook ons ander inheemse tale.
Lees ook:
Wat sou die impak van die Vierde Nywerheidsrewolusie op vertaling en tolking kon wees?
"Om siele vir die Here te wen" – die pastorale rol in tye van kunsmatige intelligensie
Skepsel deur Willem Anker: ’n LitNet Akademies-resensie-essay