

|
||||||||
Opsomming
Hierdie artikel het die gebruik van ChatGPT-4o as kunsmatige intelligensie-gebaseerde assesseringshulpmiddel ondersoek en dit vergelyk met tradisionele dosentgebaseerde assessering van akademiese opstelle in ’n Afrikaans 2-module vir tweedejaar-onderwysstudente. Ons het ’n gemengde metode-benadering gebruik om verskille in puntetoekenning (meting) en terugvoer tussen die twee benaderings te ontleed. Bevindinge het getoon dat ChatGPT-4o deurlopend hoër punte toegeken het, veral in kategorieë soos taal en struktuur, maar nie nuanses en konteksspesifieke faktore kon identifiseer wat menslike assessering uniek maak nie. Daar was ook ’n statisties beduidende verskil tussen die gemiddelde punte wat deur die dosent en ChatGPT-4o toegeken is. Ons het bevind dat hoewel ChatGPT-4o vinnige en objektiewe terugvoer gebied het, dit nie volledig aan die beginsels van gehalteassesseringspraktyke voldoen het nie. Dié multimodale taalmodel se beperkinge het ’n gebrek aan kontekstuele bewussyn en onvoldoende belyning met spesifieke leerdoelwitte ingesluit. Ons het ook bevind dat menslike moderering nodig bly om KI-gebaseerde assesseringsuitsette te ondersoek. Die artikel het die potensiaal van KI (veral groottaalmodelle) om dosente te ondersteun, beklemtoon, maar ook teen ’n uitsluitlike afhanklikheid van hierdie tegnologie gewaarsku. Ons het verdere navorsing aanbeveel oor die verfyning van KI-gebaseerde assesseringsmetodes en die integrasie daarvan in opvoedkundige praktyke.
Trefwoorde: assessering; Afrikaans 2; akademiese opstelle; ChatGPT-4o; gehalteassesseringspraktyke; KI-gebaseerde assesseringshulpmiddel; kunsmatige intelligensie (KI); tradisionele dosentgebaseerde assessering
Abstract
Assessment of academic essays: a comparative study between ChatGPT-4o as an AI-based assessment tool and traditional lecturer-based assessment
The assessment of student assignments is a fundamental component of the educational process, serving both formative and summative functions. Traditional assessment of assignments relies on lecturer expertise to evaluate student performance and provide targeted feedback. However, recent advancements in artificial intelligence (AI) have raised questions about the feasibility of AI-based assessment tools as a complement or alternative to human evaluation. This study explores the extent to which ChatGPT-4o, a multimodal language model, can perform the assessment (grading and evaluation/feedback) of essays when measured against the principles of quality assessment.
The rationale for this research stems from the growing need to understand the capabilities and limitations of AI in educational assessment. Given the increasing workload on lecturers, AI tools could offer a means to streamline assessment processes by providing quick, consistent, and potentially objective evaluations. However, concerns remain regarding AI’s ability to assess complex academic writing, particularly in capturing critical analysis, argumentation, and contextual relevance. Ethical considerations, including AI bias, transparency, and the impact on student learning, also play a crucial role in evaluating AI’s potential in educational settings.
The primary research question asks whether ChatGPT-4o adheres to the principles of quality assessment when evaluating and grading academic essays. Secondary questions explore key debates surrounding AI-based assessment in higher education, compare AI-generated and lecturer-based assessment results, and examine ethical implications and potential biases in AI evaluation.
The research aims to:
- Determine whether ChatGPT-4o meets quality assessment standards, specifically when assessing academic essays.
- Explore key debates about the use of large language models as an AI-based assessment tool in the higher education context.
- Compare the assessment results of ChatGPT-4o and a human lecturer.
- Identify ethical concerns and biases associated with AI-based assessment tools.
This study employs a mixed-methods research design, integrating quantitative and qualitative analyses. The sample consists of 18 academic essays from second-year education students at a private higher education institution in Gauteng, South Africa. The assessment process utilises an analytical rubric covering five key criteria: (1) identification and discussion of appropriate texts, (2) use of relevant examples and evidence, (3) critical analysis, (4) language and structure, and (5) technical refinement. The lecturer and ChatGPT-4o independently assessed the essays using this rubric. While the lecturer provided context-specific feedback, ChatGPT-4o was given a zero-shot prompt including the assignment instructions, the rubric and the essays without additional training or contextual input. Mainly to determine what type of output ChatGPT-4o will yield with the minimum amount of input.
Results reveal a significant discrepancy between the grade assigned by the lecturer and those by ChatGPT-4o. The AI model consistently awards higher grades, with a mean difference of 14,93% in total grades. The lecturer’s grading demonstrates greater variability, indicating differentiation between strong and weak essays, whereas ChatGPT-4o’s grading remains relatively uniform. A t-test confirms that the result differences are statistically significant (p < 0,05). A Pearson correlation analysis indicates only a weak positive correlation between the two assessors, further demonstrating a lack of alignment in evaluation standards.
In terms of feedback, both ChatGPT-4o and the lecturer provide comments on key aspects of the essays. However, the lecturer offers more precise, context-driven critiques, identifying structural weaknesses, gaps in argumentation, and issues with language proficiency. In contrast, ChatGPT-4o’s feedback is more generic and lenient, often failing to penalise essays with inadequate argumentation or incorrect referencing. Additionally, the AI model does not fully recognise the contextual appropriateness of selected texts, which is a crucial aspect of the assignment.
These findings highlight several challenges in AI-based assessment. First, ChatGPT-4o lacks contextual awareness and struggles to apply academic standards effectively. While it recognises basic linguistic and structural elements, it fails to assess argument complexity and the depth of critical analysis. Second, its feedback, though detailed, is largely generic and does not provide the personalised guidance necessary for academic development. Third, the AI’s lenient grading suggests a risk of grade inflation if used without human oversight. Moreover, ethical concerns arise regarding the transparency and reliability of AI assessment tools, particularly in ensuring fairness and addressing potential biases.
Despite these limitations, ChatGPT-4o offers potential advantages. Its ability to provide instant feedback can support students’ learning processes by offering preliminary insights into their writing. However, it should be seen as a supplementary tool rather than a replacement for human assessment. The study underscores the importance of maintaining human oversight to ensure fairness, accuracy, and adherence to academic standards.
Several limitations must be acknowledged. The sample size of 18 essays is relatively small, limiting the generalisability of the findings. Additionally, the study focuses exclusively on essay assessments, whereas AI’s performance in evaluating other forms of assessment, such as multiple-choice or short answer questions, remains unexplored. Furthermore, ChatGPT-4o was not provided with institution-specific referencing guidelines, which could have influenced its assessment ability. Future research should investigate how AI can be trained with specific criteria to improve its alignment with human grading standards. Moreover, comparative studies involving multiple AI models could offer deeper insights into AI’s evolving role in assessment.
The study concludes that while ChatGPT-4o has potential as an assessment aid, it does not yet meet the standards required for independent grading of academic essays. AI lacks the ability to fully capture cultural, contextual, and finer nuances of academic writing. The discrepancies in grading and feedback suggest that AI should be used cautiously in academic assessment, with human moderation remaining essential to maintain fairness and accuracy. Ethical considerations, including transparency, bias, and reliability, must also be addressed before AI can be widely adopted in educational assessment practices. Future research should focus on refining AI assessment methodologies to enhance their reliability and effectiveness within the academic landscape.
Keywords: Afrikaans 2; academic essays; AI-based assessment tool; artificial intelligence (AI); assessment; ChatGPT-4o; quality assessment practices; traditional lecturer-based assessment
1. Inleiding
1.1 Agtergrond
Die assessering van studente se opdragte is ’n onlosmaaklike deel van die opvoedkundige proses wat in wese twee rolle vervul: eerstens om terugvoer aan studente te verskaf en tweedens om hul vordering en begrip van die onderwerp te assesseer. Tradisioneel word assessering uitgevoer deur dosente wat hul kundigheid en kennis tydens die proses gebruik. Met die vooruitgang in kunsmatige intelligensie (KI) is daar egter toenemende belangstelling in die ondersoek na die potensiële gebruik van KI binne die onderwyskonteks en spesifiek KI-gebaseerde assesseringshulpmiddels as ’n alternatiewe of aanvullende benadering tot assessering wat deur ’n mens geskied (Li en Jiang 2024).
Die rasionaal vir hierdie studie spruit uit die behoefte om die effektiwiteit en beperkings van KI-gebaseerde assesseringshulpmiddels te verstaan, spesifiek in die konteks van die assessering van opstelle in ’n Afrikaans 2-module vir tweedejaaronderwysstudente by ’n privaat hoëronderwysinstelling in Gauteng. Deur die assessering van ChatGPT-4o,1 ’n multimodale taalmodel, met dié van ’n gekwalifiseerde dosent te vergelyk, wou ons insig verkry in die haalbaarheid en betroubaarheid van die gebruik van KI as assesseringshulpmiddel in die onderrigsituasie.
Een van die belangrikste motiverings vir die ondersoek van KI-gebaseerde assessering is die potensiaal vir verhoogde doeltreffendheid en effektiwiteit. KI kan ’n groot hoeveelheid opstelle in ’n relatiewe kort tyd assesseer, wat moontlik die werkslading op dosente kan verlig en tydige terugvoer aan studente moontlik maak. Boonop kan KI ’n vorm van objektiwiteit tydens die assesseringsproses bied wat moontlike vooroordele wat uit menslike assessors kan voortspruit, beperk. Dit is egter noodsaaklik om te ondersoek of KI die komplekse nuanses van studente se skryfwerk voldoende kan assesseer.
’n Verdere rasionaal vir hierdie studie lê in die behoefte om die etiese implikasies en oorwegings wat verband hou met die gebruik van KI in die onderwys te verstaan. Etiese kwessies soos vooroordeel in KI-stelsels, deursigtigheid in assesseringshulpmiddels en die potensiële invloed op studente se akademiese en professionele geleenthede moet noukeurig ondersoek word. Deur hierdie etiese oorwegings te ondersoek, poog die studie om tot die deurlopende bespreking oor verantwoordelike en etiese integrasie van KI in opvoedkundige praktyke by te dra (Alier, García-Peñalvo en Camba 2024; Li en Jiang 2024; Salinas-Navarro, Vilalta-Perdomo, Michel-Villarreal en Montesinos 2024).
Die bevindinge van hierdie studie het praktiese gevolge vir dosente, beleidmakers en kurrikulumontwikkelaars bestudeer. As groottaalmodelle, of in hierdie geval multimodale taalmodelle soos ChatGPT-4o, akkuraat en betroubaar in die assessering van studente se opstelle is, kan dit gebruik word om menslike assessering aan te vul of te verbeter, wat meer doeltreffende assesseringsprosesse bied. Aan die ander kant, as beperkings en uitdagings geïdentifiseer word, sal dié studie dosente inlig oor die belangrikheid van die handhawing van menslike kundigheid en oordeel in die assesseringsproses, terwyl KI as ’n ondersteunende hulpmiddel gebruik word.
1.2 Navorsingsvraag
1.2.1 Primêre navorsingsvraag
In watter mate voldoen ChatGPT-4o as ’n KI-gebaseerde assesseringshulpmiddel aan die beginsels van hoëgehalteassesseringspraktyke ten opsigte van akademiese opstelle?
1.2.2 Sekondêre navorsingsvrae
- Wat is die sleuteldebatte oor die gebruik van groottaalmodelle as KI-gebaseerde assesseringshulpmiddels in die hoëronderwyskonteks?
- Hoe vergelyk die assesseringsresultate van akademiese opstelle tussen ChatGPT-4o met ’n dosent s’n?
- Wat is die etiese oorwegings en moontlike vooroordele wat met die gebruik van ’n KI-gebaseerde assesseringshulpmiddel vir die assessering van akademiese opstelle verband hou?
1.3 Navorsingsdoelwitte
1.3.1 Primêre navorsingsdoelwit
Om te ondersoek of ChatGPT-4o as ’n KI-gebaseerde assesseringshulpmiddel aan die beginsels van gehalteassesseringspraktyke ten opsigte van akademiese opstelle voldoen.
1.3.2 Sekondêre navorsingsdoelwitte
- Om sleuteldebatte oor die gebruik van groottaalmodelle as KI-gebaseerde assesseringshulpmiddel in die hoëronderwyskonteks te ondersoek.
- Om die assesseringsresultate van akademiese opstelle tussen ChatGPT-4o en die gekwalifiseerde dosent te vergelyk.
- Om die etiese oorwegings en moontlike vooroordele wat verband hou met die gebruik van ’n KI-gebaseerde assesseringshulpmiddel vir die assessering van akademiese opstelle te ondersoek.
2. Teoretiese begronding
2.1 Verduideliking van die begrip assessering
Verskeie opvoedkundige rolspelers verduidelik die begrip assessering op uiteenlopende wyses. Hierdie verskillende perspektiewe spruit voort uit die spesifieke kontekste en leerkulture waarin die rolspelers werk, wat die gebruik en implementering van assessering beïnvloed (Lombard en Van Tonder 2023). Dit lei daartoe dat die implementering van assessering dikwels óf ’n produkgerigte, óf ’n prosesgerigte benadering aanneem, of ’n kombinasie van albei.
Die produkgerigte benadering fokus op die eindresultate van die leerproses, met klem op die mate waarin studente spesifieke leerdoelwitte behaal (Bester en Le Hanie 2024). Hierdie benadering is waardevol, aangesien dit konkrete doelwitte en standaarde stel wat maklik gemeet en geëvalueer kan word, wat die gehalte van onderrig en die leerverwagtinge van studente verhoog. In teenstelling hiermee, fokus die prosesgeoriënteerde benadering op die leerproses self. Dit beklemtoon dat assessering nie net ’n finale evaluering is nie, maar ook ’n deurlopende proses van konstruktiewe terugvoer en remediërende ondersteuning om leer te verbeter (Bester en Le Hanie 2024). Die ideale benadering is dus ’n vermenging van die produk- en prosesgerigte benaderings, wat die voordele van albei perspektiewe benut.
’n Geïntegreerde benadering tot assessering neem die produk- en prosesgerigte perspektiewe in ag en behels die sistematiese versameling van inligting oor studente se leer (Lambert en Lines 2000:4; Walvoord 2004). Dit maak gebruik van beskikbare tyd, kennis, kundigheid en hulpbronne om ingeligte besluite te neem oor hoe leer verbeter kan word (Lambert en Lines 2000:4; Walvoord 2004).
In aansluiting hierby beklemtoon Booyse (2024) die belangrikheid van konstruktiewe terugvoer in die assesseringsproses deur na assessering as ’n gesprek te verwys, wat die interaktiewe aard daarvan belig. Lombard en Van Tonder (2023) stel voor dat hierdie gesprekvoering tussen sleutelrolspelers, soos die onderwyser/dosent, student, ouers en skoolbestuurspanne, aan die einde van ’n akademiese tydperk (byvoorbeeld semester, kwartaal of jaar) moet plaasvind. Booyse (2024) verskil egter van hierdie standpunt en voer aan dat die assesseringsgesprek deurlopend tydens die onderrig- en leerproses moet plaasvind om aktiewe leer te bevorder. Die term assessering is afgelei van die Latynse werkwoord assidere, wat beteken om saam met of langs die student te sit tydens die onderrig- en leerproses (Lombard en Van Tonder 2023; Booyse 2024). Dit impliseer die interaktiewe en deurlopende aard van assessering en beklemtoon die belangrikheid van samewerking tussen sleutelrolspelers. Volgens Lombard en Van Tonder (2023) behoort ’n geskikte en omvattende beskrywing van assessering voorsiening te maak vir a) ’n balans tussen ’n produk- én prosesgerigte benadering, b) die betrokkenheid van die onderwyser/dosent én die student, aangesien assessering albei partye moet bevoordeel, en c) dat die uitkomste van assessering altyd op leer gerig moet wees. Hierdie artikel poog om assessering binne hierdie omvattende kriteria te benader.
2.2 Assesseringsmetodologie
Die integrasie van onderrig, leer en assessering is noodsaaklik om leerdoelwitte suksesvol te bereik. Om hierdie geïntegreerde benadering te verseker, is dit belangrik dat konstruktiewe belyning toegepas word in die keuse van onderrig-, leer- en assesseringstrategieë. Konstruktiewe belyning behels ’n doelgerigte integrasie van leerinhoud, onderrigmetodes en assessering om leerdoelwitte doeltreffend te bereik (Biggs 2003). Verder word konstruktiewe belyning dikwels as die norm waarop gehalteassesseringspraktyke gegrond word beskou (Biggs 2003; Salinas-Navarro e.a. 2024). Daarom behoort die beginsels van gehalteassesseringspraktyke nie slegs betrekking te hê op die assessering van toetsitems nie, maar moet dit ook toegepas word in die onderrig- en leerproses as geheel (sien tabel 1 hier onder vir meer inligting hieroor).
Ten einde hierdie konstruktiewe belyning te verwesenlik en onderrig-, leer- en assesseringspraktyke van gehalte te verseker, stel Lombard en Van Tonder (2023) bepaalde vrae voor wat dosente hulleself kan afvra:
- Wat moet studente aan die einde van ’n leerervaring kan demonstreer?
- Watter onderrig- en leeraktiwiteite is die geskikste om leerder-/studentebetrokkenheid te bevorder sodat die leerdoelwitte en assesseringskriteria suksesvol bereik kan word?
- Hoe sal die suksesvolle bereiking van hierdie leerdoelwitte en assesseringskriteria geëvalueer word?
Die antwoorde op hierdie vrae sal bepaal word deur die spesifieke onderrig- en leerkonteks, die aard van die module wat aangebied word, sowel as studente se sosioëkonomiese agtergrond en veelvuldige leerbehoeftes. Dit is belangrik om kennis te dra van verskillende onderrigstrategieë, -metodes en -tegnieke wat in ’n leerervaring gevolg kan word om effektiewe leer te verseker.
Volgens Killen en Hattingh (2022) kan onderrigstrategieë soos direkte onderrig, besprekings, kleingroepwerk, samewerkende leer, probleemoplossing, ondersoek en rolspel toegepas word. Onderrigmetodes sluit hierdie strategieë in, maar kan ook metodes soos vertel-, demonstrasie-, projek-, vrae- en die legkaartmetode omvat (Killen en Hattingh 2022). Onderrigtegnieke, daarenteen, behels tegnieke soos die vraag-, motiverings-, dril-, demonstrasie-, illustrasie-, storievertel- en ondersteuningstegniek.
Aangesien hierdie artikel meer op assessering as onderrig- en leerpraktyke fokus, sal daar vervolgens in meer besonderhede gekyk word na die verskillende assesseringsmetodologieë wat dosente in hul leerervarings kan implementeer om konstruktiewe belyning te verseker, wat bydra tot die verwesenliking van gehalteonderrig en effektiewe leer. Assesseringsmetodologie word as ’n oorkoepelende term beskou en beskryf hoe assessering uitgevoer gaan word (Lombard en Van Tonder 2023). Assesseringsmetodologie veronderstel assesseringsbenaderings, -metodes, -instrumente en -hulpmiddels.
Assesseringsbenaderings kan op twee maniere geskied, naamlik formeel of informeel. Formele assessering behels dat punte vir prestasie- en bevorderingsdoeleindes aangeteken word, terwyl informele assessering dikwels nie punte behels nie (Lombard en Van Tonder 2023). Indien informele assessering wel punte behels, word hierdie punte nie vir formele doeleindes soos prestasie en bevordering aangeteken nie (Bester en Le Hanie 2024). Informele assessering word dikwels gebruik om voorkennis te toets en om leerders/studente se deurlopende vordering te monitor met die doel om steierwerk2 (“scaffolding”) te bied (Bester en Le Hanie 2024).
Die assesseringsmetode verwys na die formaat waarin die assessering sal plaasvind, byvoorbeeld waarneming, skriftelike of mondelinge vraagstelling, verslagdoening en produkevaluering (Lombard en Van Tonder 2023). Verder is die assesseringstaak of -instrument die spesifieke vorm wat die assesseringsmetode aanneem, soos rolspel, skriftelike opdragte, demonstrasies, gevallestudies, projekte en opstelle (Lombard en Van Tonder 2023). Boonop sluit assesseringshulpmiddels onder andere merkskemas, memorandums, nasienrubrieke, kontrolelyste en graderingskale in, wat gebruik word om ’n taak te assesseer (Lombard en Van Tonder 2023).
2.3 Beginsels vir gehalteassesseringspraktyke
Gehalteassesseringspraktyke staan sentraal in die assesseringsproses. Om die betroubaarheid van assesseringsgeleenthede en -resultate te verseker, is dit nodig dat daar aan bepaalde beginsels of gehaltekriteria voldoen moet word. Lombard en Van Tonder (2023) bied ’n oorsig van gekose Suid-Afrikaanse bronne wat ’n groot verskeidenheid beginsels vir gehalteassesseringspraktyke uitbeeld. Hierdie beginsels veronderstel onder andere: betroubaarheid (ook bekend as konsekwentheid), geldigheid, integriteit, regverdigheid (ook bekend as geregtigheid), deursigtigheid, onderskeidingsvermoë, balans, sensitiwiteit vir taal, geloofwaardigheid in die vorm van ondersteunende administratiewe prosedures, sinvolheid, outentisiteit, kognitiewe kompleksiteit, balans, lewensvatbaarheid, veralgemeenbaarheid en oordraagbaarheid (Lombard en Van Tonder 2023). Alhoewel daar verskeie beginsels vir gehalteassesseringspraktyke bestaan, word betroubaarheid, geldigheid en regverdigheid as die drie hoofbeginsels vir gehalteassesseringspraktyke gekenmerk (Lombard en Van Tonder 2023).
Betroubaarheid vereis dat daar duidelike bewyse van konsekwentheid in die interpretasie van assesseringsresultate is. ’n Assesseringsopdrag kan slegs as betroubaar beskou word wanneer verskillende assessors, op verskillende tye, tot dieselfde resultaat kom (Lundie 2010; Lombard en Van Tonder 2023). In teenstelling hiermee, is geldigheid gefokus op die toepaslikheid, bruikbaarheid en betekenisvolheid van die afleidings wat uit die assesseringsresultate gemaak word. Hierdie afleidings is slegs geldig indien die assesseringstaak werklik gemeet het wat dit bedoel was om te meet (Lombard en Van Tonder 2023; Le Grange en Beets 2005; Lundie 2010). Le Grange en Beets (2005) beklemtoon dat geldigheid een van die belangrikste beginsels is om assesseringspraktyke as goed te klassifiseer. Regverdigheid, aan die ander kant, verwys na die noodsaak dat assessering redelik, onbevooroordeeld moet wees. ’n Regverdige assessering bied gelyke geleenthede vir alle studente om die leerdoelwitte te demonstreer (Lundie 2010; Lombard en Van Tonder 2023).
Die onderstaande tabel illustreer bepaalde beoordelingskriteria waaraan die beginsels van betroubaarheid, geldigheid en regverdigheid gemeet kan word.
Tabel 1. Assesseringsfases en beginsels van gehalteassesseringspraktyke
| Assesseringsfase | Betroubaarheid | Geldigheid | Regverdigheid |
|---|---|---|---|
| Pre‑assesseringsfase | Aantal toetsitems: Die aantal items in ’n toets kan die betroubaarheid daarvan beïnvloed. Toetse met min items kan minder betroubaar wees. | Toepaslikheid van toetsitems: Die inhoud van die toetsitem moet toepaslik, duidelik en meetbaar wees in terme van die leerdoelwitte en assesseringskriteria wat bereik moet word. | Oop en deursigtige assessering: Die assesseringsproses moet duidelik en deursigtig wees, met goed gedefinieerde kriteria wat objektief toegepas word. |
| Uitskakeling van raaiwerk: Raaiwerk moet vermy word. Waar‑of‑onwaar‑vrae sonder verduidelikings is onbetroubaar. Geslote toetsitems voorsien nie die assessor van die nodige inligting om te bepaal of aktiewe leer3 plaasgevind het nie. | Verteenwoordiging van leerinhoud: Die inhoud van die toetsitem moet voldoende verteenwoordigend wees van die inhoud wat studente geleer het. Byvoorbeeld: Geen manipulering van die kurrikulum word gedoen sodat assessering makliker kan geskied nie, geen persoonlike vertolkings oor die aard van ’n vak en geen verskuilde agendas word bevorder nie. | Uitskakeling van diskriminasie: Diskriminasie, gebaseer op faktore soos geslag, moet tydens die samestelling van die toetsitem vermy word. | |
| Duidelike instruksies: Instruksies vir toetsitems moet duidelik en verstaanbaar vir die beoogde teikengroep wees. | Kundigheid van die assessor: Assessors moet kundig in die betrokke vakgebied wees om geldigheid in die saamstel en assessering van die toetsitems te verseker. | Alternatiewe en diverse assesseringsgeleenthede: ’n Reeks alternatiewe assesseringsgeleenthede (projekte, rolspel) of verskillende vraagtipes in ’n toetsitem word gebruik om voorsiening vir studente met diverse leerbehoeftes te maak. | |
| Duidelike nasienriglyne: Duidelike riglyne moet verskaf word wat die interpretasie van studente se antwoorde in ag neem. Byvoorbeeld: Opsteltoetsitems kan meer subjektief van aard wees, en daarom is duidelike en volledige nasienriglyne nodig om konsekwentheid in die assessering daarvan te verseker. | Geskikte moeilikheidsgraad: Die moeilikheidsgraad van die toetsitems moet op die geskikte NKR‑vlak vir die bepaalde jaargroep wees. | Pre‑moderering: Toetsitems moet pre‑moderering ondergaan om onregverdigheid of vooroordeel te voorkom. | |
| Assesseringsfase | Leeromgewing vir die aflê van assesseringsgeleenthede: Die leeromgewing waarin die toets afgelê word, moet gunstig en bevorderlik wees vir assessering om effektief en sonder steurnisse plaas te vind. | Nakoming van assesseringsreëls: Toesighouers of programmatuur moet die studente monitor tydens die aflê van die toetsitems om enige onreëlmatighede te voorkom. | Leerondersteuning tydens die aflê van die toetsitem: Daar moet voorsiening gemaak word vir die diverse leerbehoeftes van studente tydens die aflê van ’n toetsitem. Byvoorbeeld: ’n Leerder wat weens ’n leerhindernis sukkel om binne die bepaalde tydsraamwerk te skryf, kan 15 minute ekstra tyd per uur ontvang om sy of haar assessering te voltooi. |
| Post‑assesseringsfase | Konsekwente merkproses: Om konsekwentheid in die merkproses te bevorder, kan die assessor toetsitems per vraag of afdeling nasien. Byvoorbeeld: Alle antwoorde van vraag 1 moet eers gemerk word voordat na vraag 2 oorgegaan word. | Toepaslike assesseringshulpmiddels: Die gebruik van toepaslike hulpmiddels soos rubrieke, memoranda of merkskemas is noodsaaklik om geldige assesseringsresultate te verseker. | Blindelingse nasien: Assessors moet, waar moontlik, ’n blindelingse assesseringsproses toepas om vooroordeel te verminder. |
| Dubbele of meervoudige nasien kan ’n waardevolle metode wees vir die ontwikkeling van betroubare assesseringshulpmiddels. | Post‑moderering: Toetsitems moet post‑moderering ondergaan om onregverdigheid te voorkom en by te dra tot betroubaarheid en geldigheid. | ||
| Evaluering van toetsitems se resultate: Die evaluering moet gebaseer wees op kwantitatiewe (punte, persentasies) en kwalitatiewe (vlakbeskrywers, kriteria) maatstawwe, insluitend kontekstuele faktore. |
(Saamgestel uit Le Grange en Beets 2005; Lundie 2010; Killen 2018; Lombard en Van Tonder 2023)
Dit is duidelik uit die bostaande tabel dat die beginsels van betroubaarheid, geldigheid en regverdigheid mekaar komplementeer en verweef is om ’n toetsitem en die resultate daarvan as ’n gehalteassesseringsgeleentheid te klassifiseer.
2.4 Geoutomatiseerde assessering
Kunsmatige intelligensie (KI) het nie net die gesondheidsorg-, tegnologie- en besigheidsbedrywe beïnvloed nie, maar ook die onderwyssektor (Li en Jiang 2024). Dit het die manier waarop ons onderrig, leer en assesseer drasties verander (Li en Jiang 2024). Li en Jiang (2024) sowel as Salinas-Navarro e.a. (2024) verskaf verskeie voorbeelde van hoe KI die onderwyssektor verander het.
Een van die belangrikste veranderinge is die ontwikkeling van aanpasbare leerstelsels, wat persoonlike leerpaaie en inhoud kan verskaf op grond van studente se vordering en kenmerke (Salinas-Navarro e.a. 2024). Hierdie stelsels stel studente in staat om op ’n meer effektiewe manier te leer. Hierdie aanpasbare leerstelsels kan ook onmiddellike terugvoer en leiding bied, wat die leerdoeltreffendheid en uitkomste van studente verbeter (Salinas-Navarro e.a. 2024). Boonop kan onderwysdataontledingsinstrumente onderwysadministrateurs help om die gehalte van onderrig en studenteontwikkeling akkuraat te evalueer (Salinas-Navarro e.a. 2024). Dit kan tot meer ingeligte onderrigbesluite lei (Salinas-Navarro e.a. 2024).
Daarbenewens kan KI gebruik word om vinnige en professionele PowerPoint-aanbiedings te skep, wat ’n nuttige hulpmiddel vir dosente tydens lesings bied. Verder kan KI dosente ondersteun in die samestelling van assesseringshulpmiddels, soos rubrieke, mits die nodige riglyne of aanwysings vir die KI-kletsbot ingevoer word.
Verskeie riglyndokumente is vrylik op die web beskikbaar om hierdie prosesse te vergemaklik. Een so ’n dokument is A Teacher’s Guide to ChatGPT and Remote Assessments wat ’n oorsig bied van groottaalmodelle soos ChatGPT-4o en hul potensiaal om effektiewe assesseringspraktyke te ondersteun (Universitäres Institut 2023). Dit bevat algemene oorwegings vir die ontwerp van assesseringstake en idees oor hoe om ChatGPT-4o in hierdie take effektief te integreer. Nog ’n voorbeeld sluit die AI Readiness Playbook in wat deur Oregon State-universiteit saamgestel is. Hierdie boek stel onder andere ’n weergawe van die hersiene Bloom se taksonomie voor wat KI-bevoegdhede insluit.
Ten slotte bied Turnitin verskeie hulpbronne aan dosente, onder andere ’n Guide for approaching AI-generated text in your classroom (Turnitin LLC 2023). Hierdie gids bied aan dosente 11 strategieë om te oorweeg wanneer KI in die klaskamer gebruik word. Verder bied Turnitin aan dosente ’n kontrolelys wat as ’n reflektiewe maatstaf vir die opstel van assesseringstake gebruik kan word (Turnitin LLC 2023). Hierdie kontrolelys sluit betekenisvolle elemente in wat die gehalte en toepaslikheid van assesserings verseker, naamlik:
- Stem die assesseringstaak se instruksies ooreen met jou instelling se akademiese integriteitsbeleid, veral met betrekking tot die gebruik van KI-tekshulpmiddels?
- Kommunikeer die assesseringstaak se instruksies vir die aanvaarbare en onaanvaarbare gebruike van generatiewe KI-instrumente vir die studente se antwoorde?
- Bevorder die opdrag kritiese denke of redenasievermoëns? Moedig die assesseringstake studente aan om hul eie argumente te staaf?
- Vereis die assesseringstaak ’n lys van verifieerbare bronne en/of verwysings?
- Vereis die assesseringstaak dat studente ’n refleksie of verduideliking oor hul benadering tot die opdrag insluit?
- Het jy tyd vir portuurbeoordelings, konferensies en/of besprekings van die assesseringstaak ingeruim?
Die bogenoemde afdeling skets slegs ’n oorsigtelike blik op die verband tussen KI en assessering. Verskeie gepubliseerde studies fokus op die gebruik van KI om assesseringstake op te stel, die integrering van KI in assesseringstake en hoe om assesseringstake teen die gebruik van KI deur studente te beskerm. Daar is egter tans min studies, spesifiek binne die onderwyskonteks, oor hoe KI gebruik kan word om assesseringstake te assesseer en of dit aan die beginsels van gehalteassesseringspraktyke sal voldoen.
3. Literatuurstudie
3.1 Die assessering van opstelle
Die akademiese opstel as ’n assesseringsinstrument word dikwels gebruik om ’n student se kennis en vaardighede te assesseer. Die assessering van ’n akademiese opstel geskied dikwels deur middel van ’n rubriek wat óf holisties óf analities van aard is. Volgens Seßler, Fürstenberg, Bühler en Kasneci (2024) lê die onderskeid in die aard van die beoordelingsproses. ’n Holistiese benadering steun op implisiete kriteria, wat beteken dat die assessering gebaseer is op ’n algemene indruk van die opstel se gehalte, sonder dat spesifieke aspekte soos struktuur, argumentasie of taalgebruik afsonderlik geëvalueer word. Hierdie kriteria is dikwels moeilik om eksplisiet te formuleer en berus grotendeels op die beoordelaar se intuïsie en professionele oordeel. In teenstelling hiermee word ’n analitiese benadering deur eksplisiete kriteria gerig, wat duidelik geformuleerde en gestruktureerde riglyne insluit. Hierdie kriteria word gewoonlik in ’n rubriek uiteengesit en laat toe dat verskillende komponente van die opstel, soos inhoud, struktuur en taalgebruik, afsonderlik geëvalueer en bepunt word.
Volgens navorsing is daar geen noemenswaardige verskille in die uiteindelike beoordelingsuitkomste van hierdie twee benaderings nie, maar die analitiese benadering lei dikwels tot minder beoordelingsfoute as gevolg van die duidelikheid en konsekwentheid van eksplisiete kriteria (Seßler e.a. 2024). Vir die doel van die opstelle wat deel van hierdie navorsing vorm, is ’n analitiese rubriek gebruik om studente se akademiese opstelle te assesseer.
3.2 Tradisionele dosentgebaseerde assessering
Die evaluering van studente se opstelle is ’n tydsame proses dog is dit van kernbelang veral in vakke of modules waar dit deel van studente se formele assessering vorm om uiteindelik te kan bepaal of hulle die uitkomste van die module bereik het. Seßler e.a. (2024) gebruik die voorbeeld waarin opstelle in die vak Duits geassesseer moet word en toon aan dat ’n groot hoeveelheid tyd afgestaan moet word aan die merk van studente se skryfwerk. Dit sluit in voorbereiding, opvolglesse en proeflees (insluitende terugvoer wat verskaf moet word) en die uiteindelike merk van die tekste. Dit is nie anders in die Suid-Afrikaanse konteks waar die tersaaklike module Afrikaans 2 onderrig word nie.
Verskeie aspekte kan inspeel op die suksesvolle assessering van opstelle wanneer dosentgebaseerde assessering oorweeg word. Brown (2009) toon aan dat assessors se houdings, oortuigings, ingesteldhede, energievlakke, kundigheid en mag tot die puntetoekenning (meting) van ’n opstel kan bydra. Om ’n rubriek te gebruik waarin die kriteria eksplisiet uiteengesit word, is oor die algemeen meer konsekwent vir die merk van ’n opstel en kan die impak van die faktore wat nie nou verband hou met die konstruk wat gemeet word nie, verminder (Brown 2009). Verder beveel Brown (2009) ook aan dat twee merkers per opstel die betroubaarheid van die meting verhoog. In ’n kapasiteitsbeperkte konteks berus die bepaling van studente se nakoming van assesseringsvereistes op die dosent se begrip van die onderrigkonteks en gehalteassesseringsbeginsels. Brown (2009) toon aan dat, wanneer die nodige kapasiteit ontbreek, ander vorme van assessering oorweeg moet word of geoutomatiseerde opstelgradering gebruik moet word. Die laasgenoemde vorm van gradering hou egter ook uitdagings in.
3.3 Die gebruik van groottaalmodelle vir assessering
Geoutomatiseerde opstelgradering word reeds vanaf 1966 ontwikkel, maar volgens Seßler e.a. (2024) blyk dit of die meeste van hierdie geoutomatiseerde modelle grotendeels op taal eerder as inhoud fokus en plaas dit nie genoeg klem op hoe die teks as ’n eenheid bymekaar gevoeg is nie. Voorts steun ’n groot deel van hierdie graderingshulpmiddels op statistiese eienskappe om eindelik een holistiese finale punt toe te ken. Die data hiervoor is ook meestal op Engels gebaseer.
Die koms van groottaalmodelle het ander moontlikhede vir geoutomatiseerde opstelgradering beskikbaar gestel. Verskeie studies toon reeds belowende resultate tydens die assessering van opstelle deur van GPT-modelle gebruik te maak, maar daar is steeds beperkings. Byvoorbeeld: Die resultate van die uitset van die GPT-modelle blyk te verbeter wanneer riglyngedrewe-aansporingsboodskappe soos “few-shot learning”- en “chain-of-thought”- (CoT) aansporingsboodskappe gebruik word. Die resultate is ook minder akkuraat met geen uitgebreide konteksspesifieke aansporingsboodskappe nie (beter bekend as “zero shot”-aansporingsboodskappe). Voorts is die meeste studies wat beskikbaar is slegs op Engelse opsteldata gebaseer. Dit verskaf meestal holistiese finale punte of gebruik ’n beperkte hoeveelheid kunsmatige kriteria as deel van die studie (Seßler e.a. 2024).
Seßler e.a. (2024) het in hul studie bevind dat verskeie groottaalmodelle nog nie gereed is om opstelle outomaties te assesseer nie. Dié studie toon aan dat groottaalmodelle soos GPT-4 en o1, ten spyte van ’n hoë mate van belyning met menslike graderings betreffende taalverwante kriteria, geneig is om hoër algehele punte toe te ken. Hul studie beklemtoon dus dat daar met omsigtigheid met groottaalmodelle omgegaan moet word en bepaalde aansporingsboodskappe-strategieë geïmplementeer moet word om die akkuraatheid van die opstelassessering te verhoog. Oopbronmodelle soos LLaMA 3 en Mixtral toon swak resultate en dui daarop dat dit nog nie gereed is vir die gebruik binne ’n opvoedkundige konteks nie mits daar beduidende verbeteringe in die konsekwentheid en belyning met menslike standaarde aangebring word (Seßler e.a. 2024).
Vir die doel van hierdie navorsing is geen uitgebreide konteksspesifieke aansporingsboodskappe (“zero shot”-aansporingsboodskappe) gebruik, juis om te bepaal hoe ChatGPT-4o vaar tydens die assessering van opstelle sonder dat dit vooraf “opgelei” is om ’n bepaalde taak te verrig. Later in hierdie artikel sal daar wel verwys word na opvolgende riglyngedrewe-aansporingsboodskappe wat deel vorm van denkrigtingaansporingsboodskappe (beter bekend as CoT-aansporingsboodskappe) aangesien daar steeds nie enige voorbeelde of opleidingsdata aan ChatGPT-4o verskaf is nie.
4. Navorsingsmetodologie
4.1 Navorsingsbenadering en -ontwerp
Ons het ’n gemengdemetode-navorsingsontwerp gebruik en sowel die meting (puntetoekenning) as die evaluering (terugvoer) van die tersaaklike opstelle vorm deel van die vergelykende benadering. Beide die gekwalifiseerde dosent en ChatGPT-4o het die opstelle geassesseer om die vergelykende studie uit te kan voer. Meer inligting oor die data-insameling kan in die toepaslike afdeling gevind word. Die gekwalifiseerde dosent het nege jaar ervaring in die hoëronderwyskonteks en beskik oor ’n MA in Algemene Taal- en Literatuurwetenskap en ’n NGOS-kwalifikasie. Hierdie dosent het voorheen aan internasionale projekte deelgeneem, insluitend projekinisiatiewe wat daarop gemik is om hulpmiddels te ontwikkel wat studente in hul akademiese loopbaan ondersteun en meertaligheid binne die hoëronderwyskonteks bevorder.
4.2 Navorsingspopulasie
Die studiepopulasie was tweedejaar-onderwysstudente wat die Afrikaans 2-module ten tyde van hierdie studie voltooi het.
4.3 Steekproefneming
Ons het ’n niewaarskynlikheid-steekproefneming, spesifiek ’n gerieflikheidsteekproefneming gebruik. Hierdie steekproefnemingsmetode was die geskikste vir hierdie studie, aangesien ons toegang tot die Afrikaans 2-module van tweedejaar-onderwysstudente by ’n privaat hoëronderwysinstelling in Gauteng gehad het.
4.4 Etiese klaring
Etiese oorwegings behoort in die hele navorsingsproses van ’n navorsingstudie oorweeg te word, naamlik die omvang van die navorsing wat uitgevoer word, die konteks waarbinne die navorsing plaasvind, asook die toepaslikheid en betroubaarheid van navorsingsmetodes vir die insameling, ontleding en rapportering van bevindinge.
Hierdie navorsingstudie is eerstens aan die betrokke hoëronderwysinstelling se navorsingskomitee vir etiese goedkeuring en uitvoering van die studie voorgelê. Met goedkeuring van bogenoemde etiese klaring is ingeligte toestemming, in die geval van tweedejaar-onderwysstudente in die Afrikaans 2-module, verkry. Alle data is vertroulik hanteer, en die anonimiteit van die deelnemers is verseker deur die verwydering van persoonlike identifikasie-inligting op die data-dokumente en die toewysing van kodenommers vir die analise en dokumentering van bevindinge.
4.5 Data-insameling
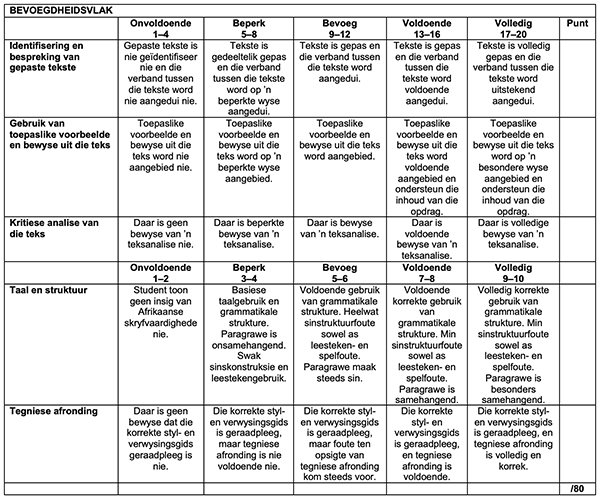
’n Voorafbepaalde analitiese rubriek, ontwerp deur die dosent van die betrokke Afrikaans 2-module, is as basis vir die assessering van die opstelle gebruik. Hierdie analitiese rubriek het dimensies soos identifisering en bespreking van gepaste tekste, gebruik van toepaslike voorbeelde en bewyse uit die teks, kritiese analise van die teks, taal en struktuur en tegniese afronding met duidelike kriteria en puntetoekenning ingesluit. Sien addendum A vir die opdraginstruksies en rubriek. Let wel dat hierdie rubriek nie gevalideer is nie.
Die data-insamelingsproses het uit drie fases bestaan:
Fase 1
Hierdie fase het die insameling van akademiese opstelle van tweedejaar-onderwysstudente in die Afrikaans 2-module sowel as die ingeligte toestemming van die navorsingspopulasie behels. Diegene wat nie ingestem het om hul opstelle vir hierdie navorsing beskikbaar te stel nie, is verwyder.
Fase 2
Tradisionele dosentgebaseerde assessering: ’n Gekwalifiseerde dosent wat in Afrikaans-onderwys spesialiseer, het die opstelle aan die hand van die voorafbepaalde rubriek geassesseer. Die dosent se toegekende punt en terugvoer is vir ontleding ingesamel.
Fase 3
ChatGPT-4o-gebaseerde assessering: Die gekose opstelle is in ChatGPT-4o ingevoer, en die model het assesseringsterugvoer gegenereer op grond van die voorafbepaalde rubriek wat deel van die aansporingsboodskap gevorm het. Die gegenereerde toegekende punt (meting) en terugvoer (evaluering) van ChatGPT-4o is aangeteken vir ontleding. Die hoofdoel hier was om te bepaal hoe hierdie multimodale taalmodel se assessering as uitset vanuit die staanspoor lyk. Die volgende aansporingsboodskap is aan ChatGPT-4o voorsien:
Ek wil graag hê dat jy as ’n assessor moet optree vir ’n spesifieke opdrag vir ’n tweedejaarsmodule vir ’n hoëronderwysinstelling. Die module se naam is Afrikaans 2. Ek gaan vir jou die opdrag se instruksies en rubriek gee aan die hand waarvan die opdragte gemerk moet word. Daarna sal ek die opdragte een vir een oplaai. Verskaf asb. vir elke opdrag ’n punt aan die hand van hierdie rubriek. Maak asb. seker dat daar ’n punt verskaf word vir elke kriteria.
Saam met die bostaande aansporingsboodskap is die opdraginstruksies en rubriek verskaf.
Vir verdere verfyning van die meting van die opstelle deur ChatGPT-4o is ’n tweede en ’n derde riglyngedrewe-aansporingsboodskap verskaf om te bepaal of daar ander metings verskaf word (sien “CoT”-aansporingsboodskap). Die uitsette van hierdie tweede en derde rondte het nie deel van die data-ontleding gevorm nie, aangesien daar geen noemenswaardige verskil was van die eerste uitset wat deur ChatGPT-4o verskaf is nie en dit nie tot ’n produktiewe ontleding sou bydra nie.
4.6 Data-ontleding
Hierdie navorsingstudie het ’n gemengdemetode-benadering gebruik. ’n Statistiese ontleding is voltooi vir die kwantitatiewe data-ontleding, en ’n inhoudsontleding vir die kwalitatiewe data. Dit het ’n stelselmatige proses behels waartydens die akademiese opstelle van tweedejaar-onderwysstudente in ’n Afrikaans 2-module se assessering deur ChatGPT-4o en die dosente vergelyk is ten einde die navorsingsvrae te beantwoord en aan die navorsingsdoelwitte te voldoen. Dit het behels dat beide die meting sowel as die evaluering deur die “assessors” met mekaar vergelyk is. Die evaluering (ook terugvoer) is deur middel van ’n inhoudsontleding gedoen en volgens die kriteria waaraan die opstelle moes voldoen, gekategoriseer. Volgens Engelbrecht (2016) kan die gebruik van inhoudsontleding sleutels ondersoek wat in rou data opgesluit is. Hierdie sleutels is gebaseer op ooreenkomste en verskille in tekste wat bepaalde teorieë bevestig of uitlig al dan nie. Hierdie data-ontledingsproses was induktief van aard, aangesien tekstuele data ontleed is om bevindinge en gevolgtrekkings te maak.
5. Bevindinge
Die 18 opstelle is deur middel van ’n analitiese rubriek wat uit vyf kriteria bestaan het, bepunt. Vir die doel van die kwantitatiewe ontleding tussen die resultate word die volgende beskrywende statistiese data verskaf. Die assessering van die dosent en ChatGPT-4o is in aanmerking geneem. Let wel dat slegs die eerste uitset van ChatGPT-4o vir die doel van hierdie studie gebruik is. Alhoewel “CoT”-aansporingsboodskappe vir verdere uitsette aan ChatGPT-4o verskaf is, het die uiteindelike meting van die opstelle nie genoegsaam van die eerste uitset verskil om ’n produktiewe vergelyking te tref nie. Die navorsers het daarom besluit om slegs die eerste meting en evaluering van ChatGPT-4o te gebruik.
Tabel 2. Opsomming van beskrywende statistiek van metings deur die dosent en ChatGPT-4o
Klik op die tabel vir ’n groter weergawe.

Uit tabel 2 kan daar reeds ’n verskil tussen die punte wat die dosent toegeken het in vergelyking met ChatGPT-4o waargeneem word. Die gemiddelde totale punt tussen die dosent en ChatGPT-4o s’n verskil met 11,94 punte, d.w.s. 14,93%. Verder is die hoogste punt (maksimum) wat die dosent toegeken het per kriterium telkens effens meer of dieselfde as ChatGPT-4o s’n. Die laagste punt (minimum) wat ChatGPT-4o per kriterium toegeken het, is egter aansienlik hoër as die dosent s’n. Dit blyk dus dat ChatGPT-4o nie sommer lae punte sal toeken nie. Daar is ’n veel groter variasiewydte in die puntetoekenning van die dosent teenoor ChatGPT-4o wat ’n aanduiding kan wees dat die dosent ’n onderskeid tref tussen ’n opstel wat aan al die kriteria voldoen en een wat nie daaraan voldoen nie. Vanuit die variasiewydte en standaardafwyking per kriteria blyk dit of ChatGPT-4o deur die bank min of meer dieselfde punte vir die opstelle toegeken het.
Vervolgens is daar ’n t-toets uitgevoer om te bepaal of daar ’n statistiese beduidende verskil tussen die gemiddelde punt van die dosent en ChatGPT-4o s’n is. Die p-waarde per kriterium en die totale punt word hier onder in tabel 3 verskaf.
Tabel 3. Resultate van die t-toets
| p-waarde | |
| Kriterium 1 | 0,00266 |
| Kriterium 2 | 0,00224 |
| Kriterium 3 | 0,00230 |
| Kriterium 4 | 0,00023 |
| Kriterium 5 | 0,00004 |
| Totale punt | 0,00014 |
Uit die tabel is dit duidelik dat die p-waardes baie klein is (kleiner as ,05) en dus kan daar met 95% sekerheid aangetoon word dat die gemiddelde waardes tussen die twee stelle resultate (die dosent en ChatGPT-4o s’n) nie dieselfde is nie. Indien die gemiddelde waardes statisties gelyk sou wees, wat in hierdie geval nie is nie, sou ChatGPT-4o die merkwerk op dieselfde standaard as die dosent kon voltooi. Daar is egter ’n statistiese beduidende verskil tussen die puntetoekenning van die dosent teenoor ChatGPT-4o. Daarom kan ChatGPT-4o nog nie met gemak gebruik word om opstelle te merk nie en sal dit definitief eers opgelei moet word.
’n Pearson-korrelasie-ontleding is uitgevoer om die sterkte van die liniêre verband tussen die dosent se punte en ChatGPT-4o se punte te bepaal. Die korrelasiekoëffisiënte (r-waardes) vir elk van die kriteria en totale punt word hier onder in tabel 4 verskaf.
Tabel 4. Resultate van die Pearson-korrelasie-ontleding
| r-waarde | |
| Kriterium 1 | 0,37 |
| Kriterium 2 | 0,26 |
| Kriterium 3 | 0,37 |
| Kriterium 4 | 0,48 |
| Kriterium 5 | 0,29 |
| Totale punt | 0,45 |
Uit die resultate in tabel 4 hierbo en die spreidingsgrafiek (grafiek 1) hier onder (waar die gemiddelde waarde telkens herlei is na persentasie vir maklike ondersoek van die resultate per kriterium sowel as die totale punt) is daar ’n swak positiewe korrelasie (kleiner as ,6) tussen die punte wat deur die dosent in vergelyking met ChatGPT-4o toegeken is. Indien daar ’n sterker korrelasie tussen die puntetoekenning was, sou ’n duidelike opwaartse lineêre lyn waargeneem kon word. Al merk die dosent byvoorbeeld strenger as ChatGPT-4o, sou ons ’n sterker korrelasie kon verwag indien ChatGPT-4o onderskeid getref het tussen opstelle wat aan die kriteria voldoen en die wat nie doen nie. Let byvoorbeeld op na die korrelasie by Kriterium 4: Taal en struktuur waar die dosent 30% en ChatGPT-4o 60% toegeken het. In die geval waar selfs nog ’n swakker punt (20%) deur die dosent toegeken is, het ChatGPT-4o 70% toegeken.
’n Verdere voorbeeld is Kriterium 5: Tegniese afronding, waar ChatGPT-4o die meeste van die tyd 90% toegeken het en die dosent vir dieselfde opstelle onderskeidelik 20%, 30%, 40%, 60%, 70%, 80% en 90% gegee het.
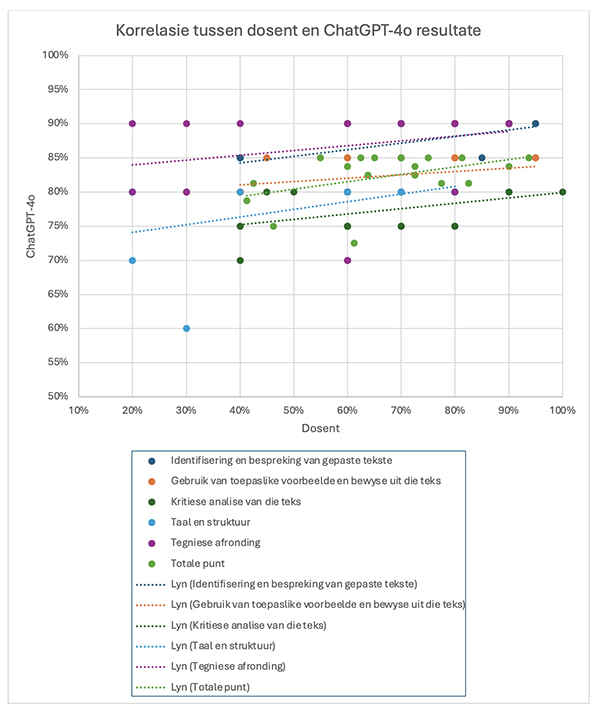
Grafiek 1. Verband tussen dosent en ChatGPT-4o se meting per kriterium
Ten opsigte van die terugvoer vir die 18 opstelle word die volgende vergelykende tabel verskaf. Die terugvoer word volgens kriterium tematies gesorteer.
Tabel 5. Vergelyking van dosent en ChatGPT-4o se terugvoer per kriterium
| Kriteria | Dosent se terugvoer | ChatGPT-4o se terugvoer | Ooreenkomste | Verskille |
| Identifisering en bespreking van gepaste tekste | Gepaste tekste word nie altyd gekies nie; onvoldoende bespreking om die verband duidelik aan te toon. | Tekste is oor die algemeen gepas; verdere analise en kontekstualisering word aangemoedig. | Beide evalueer die tekste se gepastheid en verwys na die verband tussen die tekste wat verder bespreek moet word. | Alhoewel ChatGPT-4o aanbevelings in meer besonderhede gee, word teenoorstaande perspektiewe gebied. ChatGPT-4o neem nie in ag of die tekste tot ’n produktiewe bespreking kan lei nie. |
| Gebruik van toepaslike voorbeelde en bewyse uit die teks | Voorbeelde is dikwels nie gepas nie of onvoldoende vir die argument. | Spesifieke aanhalings en voorbeelde word goed gebruik, maar meer direkte aanhalings sou verdere diepte bied. | Beide wys op die belangrikheid van toepaslike voorbeelde en aanhalings. | ChatGPT-4o sien die gebruik van voorbeelde as oorwegend voldoende, terwyl die dosent dit as onvoldoende identifiseer. |
| Kritiese analise van die tekste | Gebrekkige analise, geen duidelike argument of bespreking nie. | Analise is oor die algemeen goed, maar verdere verdieping van temas en mediumspesifieke eienskappe word aanbeveel. | Beide fokus op die behoefte aan verdieping in analise. | ChatGPT-4o sien die analise as oorwegend voldoende, terwyl die dosent dit as ’n groot leemte beskou. |
| Taal en struktuur | Duidelike struktuur ontbreek in die meeste gevalle; swak taalgebruik en sinsbou kan waargeneem word. | Taalgebruik en struktuur is oor die algemeen voldoende, maar daar is ruimte vir verbeterings. | Beide gee aandag aan die kwaliteit van taalgebruik en struktuur. | Die dosent beklemtoon die gebrek aan struktuur en swak taalgebruik, terwyl ChatGPT-4o dit oorwegend as voldoende beskou. |
| Tegniese afronding | Verwysings en formatering is nie voldoende nie. | Tegniese afronding is oor die algemeen goed, met enkele klein verbeterings nodig. | Beide verwys na tegniese aspekte soos verwysings en formatering. | Die dosent sien die tegniese afronding as onvoldoende, terwyl ChatGPT-4o dit as goed beskou. |
Tabel 5 toon die ooreenkomste en verskille tussen die dosent se terugvoer en die terugvoer wat deur ChatGPT-4o gegenereer is. Ten opsigte van ooreenkomste, fokus beide op kernareas van die spesifieke opstel, insluitend die keuse van tekste, gebruik van toepaslike voorbeelde, kritiese analise, taal en struktuur, en tegniese afronding. Albei “assessors” wys op die belang van ’n bespreking om die verband tussen die tekste aan te toon, maar die dosent sal in sommige gevalle die gepastheid van die tekste bevraagteken, terwyl ChatGPT-4o slegs ’n meer uitgebreide bespreking sal voorstel. Byvoorbeeld, indien ’n student nie tekste gekies het wat tot ’n sinvolle en produktiewe bespreking kan lei nie, het die dosent minder punte vir hierdie kriterium toegeken. Die verskil in puntetoekenning van die dosent en ChatGPT-4o weerspieël ook dié uitgangspunt (vergelyk byvoorbeeld die variasiewydte in tabel 2 hierbo). Alhoewel beide “assessors” aantoon dat die gebruik van voorbeelde uit die teks belangrik is, verskaf ChatGPT-4o telkens ’n hoër puntetoekenning en maak slegs ’n aanbeveling dat meer voorbeelde gebruik moet word. Die student word nie gepenaliseer wanneer daar nie genoegsame of gepaste voorbeelde gebruik is nie.
Verdere verskille ten opsigte van die terugvoer kan waargeneem word waar die dosent tekorte duideliker beklemtoon, soos die gebrek aan struktuur en swak taalgebruik. ChatGPT-4o bied nou weer ’n meer positiewe evaluering oor die algemeen met aanbevelings vir verbetering en dit word ook so in die puntetoekenning weerspieël. Verder beskou die dosent die tegniese afronding as problematies, terwyl ChatGPT-4o dit as voldoende evalueer met slegs klein verbeterings wat benodig word. Hierdie verskil kan moontlik toegeskryf word aan die verwagtinge wat aan studente in hierdie verband gestel is, byvoorbeeld die gebruik van ’n bepaalde verwysingsgids, die gebruik van akademiese bronne om die bespreking te ondersteun en formateringsvereistes wat aan die studente verskaf is. ChatGPT-4o is nie voorsien met die verwysingsgids nie en is moontlik ook nie vertroud met die groot hoeveelheid akademiese bronne wat moontlik met so ’n tipe opstel kan verband hou nie.
Hierdie vergelyking dui aan dat die dosent se terugvoer waarskynlik afgestem is op die spesifieke student se opstel, terwyl ChatGPT-4o meer geneig is om terugvoer op ’n breër, meer generiese manier te bied. Dit beklemtoon die waarde van menslike interaksie in onderrig, aangesien dosente meer vertroud is met die konteks van die studente en die kurrikulum, terwyl KI-toepassings soos ChatGPT-4o nuttig kan wees vir addisionele ondersteuning.
6. Bespreking
Vanuit die resultate blyk dit dat ChatGPT-4o dikwels hoër punte as die dosent toeken, spesifiek met betrekking tot kategorieë taal en struktuur en tegniese afrondings. By die kriteria identifisering van gepaste tekste, gebruik van toepaslike voorbeelde en bewyse uit die teks en kritiese analise van die teks was daar nie ’n wesenlike verskil in die dosent en KI se assesseringsresultate nie. Wanneer die gemiddelde waarde per kriterium van die dosent in ag geneem word, is dit egter minder as ChatGPT-4o s’n. Daar is na die verskil in die totale gemiddelde waarde van al die opstelle tussen die dosent en ChatGPT-4o gekyk om die holistiese beeld van die assesseringsresultate te verkry om vas te stel of gehalteassessering plaasgevind het. Die hoër punte in die kategorieë taal en struktuur en tegniese afronding kan moontlik toegeskryf word aan ’n gebrek aan duidelike voorskrifte aan ChatGPT-4o wat goeie taalgebruik en verwagte tegniese afrondings vir hierdie opdrag sou definieer. Die dosent kon regverdigheid van assessering verseker deur aan studente duidelike verwagtinge te stel teenoor ChatGPT-4o wat nie hiervan kennis gedra het nie. ChatGPT-4o neem nie kontekstuele faktore in ag nie en gevolglik kan die regverdigheid van ChatGPT-4o se assessering nie verseker word nie. ’n Positiewe punt, aan die ander kant, is dat ChatGPT-4o blindelingse assessering toepas wat die menslike element van vooroordeel en emosie by die assessering van bepaalde studente se opdragte kan uitskakel en regverdigheid verhoog.
Verder kon ChatGPT-4o deur middel van kwalitatiewe terugvoer leemtes aantoon, maar dit blyk of die puntetoekenning nie duidelik daarmee belyn is nie. Dit dui daarop dat konstruktiewe belyning tussen die gepoogde leerdoelwitte, pedagogiese strategieë, konteks van leeromgewing, kurrikuluminhoud en die assessering daarvan nie deur ChatGPT-4o verseker kon word nie.
Daar was egter klein verskille in die meting van ChatGPT-4o se pogings wat wel daarop dui dat ChatGPT-4o konsekwente assessering kan toepas. Die vraagstuk is egter of hierdie teken van konsekwente assessering bloot toegeskryf kan word aan algoritmiese reëls wat ChatGPT-4o volg. Die mate waartoe hierdie konsekwentheid as ’n teken van gehalteassessering gesien kan word, behoort dus verder ondersoek te word. Die nadeel hiervan is egter dat ChatGPT-4o nie onderskeid tref tussen ’n opstel wat aan die kriteria voldoen en een wat nie daaraan voldoen nie. Gevolglik kon ChatGPT-4o se assessering nie ten volle aan die beginsels van gehalteassesseringspraktyke voldoen nie.
7. Beperkinge van die studie
Die studie het verskeie beperkinge ingehou wat die resultate en interpretasie daarvan beïnvloed het. Eerstens kon die opdraginstruksies en analitiese rubriek moontlik in meer besonderhede wees om selfs nog duideliker onderskeid tussen goeie en swak opstelle te tref, hetsy beoordeel deur ’n menslike assessor of deur ChatGPT-4o. Tweedens was die steekproef relatief klein, bestaande uit slegs 18 opstelle, wat die veralgemeenbaarheid van die bevindinge beperk het. Derdens was die aard van die opdrag tot ’n opstel beperk, terwyl ander toetsitems soos oop vrae, geslote vrae of paragraafvrae moontlik tot ander resultate kon lei. Verder kon die gebrek aan riglyngedrewe-aansporingsboodskappe wat vir ChatGPT-4o gebruik is, ’n invloed op die model se uitset gehad het. ’n Voorbeeld hiervan is die betrokke instelling se verwysingsgids en die verwagte tegniese voorskrifte van die opstel wat nie aan ChatGPT-4o verskaf is nie. Dit het moontlik tot die model se vermoë om die tegniese afronding akkuraat te evalueer, beïnvloed. Laastens kon die spesifieke konteks van die module en die tipe assessering ook ’n rol speel, aangesien ander vakke of akademiese dissiplines moontlik verskillende resultate sou kon toon.
8. Toekomstige navorsingsvooruitsigte
In hierdie studie is die assesseringspoging van ChatGPT-4o met die dosent vergelyk. Die dosent kon die gemerkte antwoordstelle in ChatGPT-4o ingevoer het en ChatGPT-4o versoek het om dieselfde merkstyl te volg en die opstelle dienooreenkomstig te assesseer. Dit sou as ’n verdere assesseringspoging kon dien om te bepaal of ChatGPT-4o se uitsette en metings beduidend van die ander pogings verskil. Ook in watter mate die resultate van ChatGPT-4o van die dosent s’n afwyk, met die doel om die betroubaarheid van die assessering vas te stel. Betroubaarheid word bereik wanneer verskillende assessors dieselfde opdrag met dieselfde nasienriglyn op verskillende tye assesseer en dieselfde resultate verkry. Om die geldigheid van die assessering verder te bepaal, kan die opstelle, gemerk deur die dosent sowel as deur KI, in die toekoms deur ’n moderator gemodereer word. Dié resultate kan by die vergelyking ingesluit word om te bepaal of gehalteassessering plaasgevind het deur beide die dosent en KI. Hierdie studie het doelbewus geen uitgebreide konteksspesifieke aansporingsboodskappe (“zero shot”-aansporingsboodskappe) -benadering gevolg om die model se onafhanklike assesseringsvermoë te ondersoek. Die insluiting van spesifieke merkstyle of riglyne sou ’n ander dimensie tot die studie gevoeg het, wat in toekomstige navorsing verder ondersoek kan word.
9. Gevolgtrekking
ChatGPT-4o kan nuttig wees as ’n aanvanklike hulpmiddel vir evaluering, maar voldoen nie volledig aan die beginsels van gehalteassessering nie. Die resultate van KI moet steeds deur ’n menslike assessor gekontroleer of gemodereer word om akkuraatheid en volledigheid te verseker. KI is nie in staat om die samehang van die teks, die nodige konteks, kompleksiteit of spesifieke akademiese standaarde ten volle te verstaan nie. Dit impliseer dat KI nie ’n betroubare assesseringshulpmiddel is nie, maar eerder ’n aanvulling tot menslike beoordeling. Met die volgende antwoord erken ChatGPT-4o self dat dit nie ’n betroubare assessor is nie:
Alhoewel ChatGPT-4o nuttig kan wees as ’n hulpmiddel vir aanvanklike evaluering, is dit steeds belangrik dat ’n menslike assessor die opstelle finaal evalueer en volledig assesseer.
Vanuit hierdie antwoord blyk dit duidelik dat ChatGPT-4o ook nie die nodige terminologiese kennis het van die begrippe assessering, meting en evaluering nie. Dit beteken verder dat riglyngedrewe-aansporingsboodskappe wat die terme assesseer, meet en evalueer bevat, moontlik vir ChatGPT-4o ’n ander betekenis inhou en gevolglik tot ’n verskil in resultate lei. Verder het die assesseringsresultate van ChatGPT-4o en die gekwalifiseerde dosent verskil, aangesien KI nie die nodige metakognisie en pedagogiese insig het nie, wat noodsaaklik is om akademiese opstelle volledig en betroubaar binne ’n bepaalde konteks te assesseer.
Etiese oorwegings en potensiële vooroordele in die gebruik van KI-gebaseerde assesseringshulpmiddels vir akademiese opstelle sluit verskeie belangrike aspekte in. Eerstens is daar die risiko dat KI-gebaseerde assesseringshulpmiddels inherente vooroordele in die data waarop die modelle opgelei is, kan weerspieël. Dit kan lei tot onregverdige assesserings of die marginalisering van sekere perspektiewe, veral wanneer die data nie divers of inklusief is nie. Verder kan KI nie altyd die kulturele, kontekstuele en fynere nuanses van akademiese werk verstaan nie, wat ’n beperkte beoordeling tot gevolg kan hê. As gevolg hiervan moet toetsitems steeds deur dosente gemodereer word om seker te maak dat die assesseringsproses aan etiese standaarde voldoen.
Bibliografie
Alier, M., F.C. García-Peñalvo en J.D. Camba. 2024. Generative artificial intelligence in education: from deceptive to disruptive. International Journal of Interactive Multimedia and Artificial Intelligence, 8(5):5–14. DOI:10.9781/ijimai.2024.02.011.
Bester, S. en C. le Hanie. 2024. Assessering in kurrikulumstudies: teoretiese grondslae en praktiese toepassings. In Le Hanie en Bester (reds.) 2024.
Biggs, J. 2003. Teaching for quality learning at university. What the student does. 2de uitgawe. Buckingham: Society for Research into Higher Education & Open University Press.
Booyse, C. 2024. Assessering as gesprek. Die mediërende reis van assessering vir en as leer. Aanbieding gelewer by die Skoleondersteuningsentrum se WIRTEK-minikongres, 31 Augustus, Centurion.
Brown, G.T.L. 2009. The reliability of essay scores: The necessity of rubrics and moderation. In Meyer, Davidson, Anderson, Fletcher, Johnston en Rees (reds.) 2009.
Du Toit, E.R., L.P. Louw en L. Jacobs (reds.). 2023. Help! Ek is ’n studenteonderwyser. Vaardigheidsontwikkeling vir onderwyspraktyk. Pretoria: Van Schaik.
Engelbrecht, A. 2016. Kwalitatiewe navorsing: data-insameling en -analise. In Joubert, Hartell en Lombard (reds.) 2016.
Joubert, I., C. Hartell en K. Lombard (reds.). 2016. Navorsing: ’n Gids vir die beginnernavorser. Pretoria: Van Schaik.
Killen, R. 2018. Teaching strategies for quality teaching and learning. 2de uitgawe. Kaapstad: Juta.
Killen, R. en A. Hattingh. 2022. Teaching strategies for quality teaching and learning. 3de uitgawe. Kaapstad: Juta.
Lambert, D. en D. Lines. 2000. Understanding assessment: Purpose, perceptions, practice. New York: RoutledgeFalmer.
Le Grange, L. en P. Beets. 2005. (Re)conceptualizing validity in (outcomes-based) assessment. South African Journal of Education, 25(2):115–9. https://hdl.handle.net/10520/EJC32029.
Le Hanie, C. en S. Bester (reds.). 2024. ’n Inleidende perspektief op kurrikulumstudies. Pretoria: Van Schaik.
Le Hanie, C. en J. Pottas. 2025. ’n Kritiese ondersoek na Nearpod se rol in die bevordering van aktiewe leer binne ’n kontakmodel in die hoëronderwyskonteks. LitNet Akademies, 22(1):426–52.
Li, X. en Y. Jiang. 2024. Artificial intelligence in education: opportunities, current status and prospects. Geographical Reseach Bulletin, 3:146–74. https://doi.org/10.50908/grb.3.0_146.
Lombard, K. en F. van Tonder. 2023. Klaskamerassessering. In Du Toit, Louw en Jacobs (reds.) 2023.
Lundie, S. 2010. Ondersoek na uitkomsgebaseerde assessering in Suid-Afrikaanse skole. MEd-verhandeling, Noordwes-Universiteit.
Meyer, L.H., S. Davidson, H. Anderson, R. Fletcher, P.M. Johnston en M. Rees. (reds.). 2009. Tertiary assessment and higher education student outcomes: Policy, practice and research. Wellington: Ako Aotearoa.
Salinas-Navarro, D.E., E. Vilalta-Perdomo, R. Michel-Villarreal en L. Montesinos. 2024. Using generative artificial intelligence tools to explain and enhance experiential learning for authentic assessment. Education Sciences, 14(1):83. https://doi.org/10.3390/educsci14010083.
Seßler, K., M. Fürstenberg, B. Bühler en E. Kasneci. 2024. Can AI grade your essays? A comparative analysis of large language models and teacher ratings in multidimensional essay scoring. Proceedings of 15th International Conference on Learning Analytics and Knowledge (LAK ’25). ACM, New York, NY, VSA, 11 bladsye. https://arxiv.org/pdf/2411.16337.
Turnitin LLC. 2023. Guide for approaching AI-generated text in your classroom. Turnitin.
Universitäres Institut. 2023. A teacher’s guide to ChatGPT and remote assessments. UniDistance Suisse.
Walvoord, B.E. 2004. Assessment clear and simple: A practical guide for institutions, departments, and general education. San Francisco: Jossey-Bass.
Eindnotas
1 ChatGPT-4o is vir die doel van hierdie studie gekies, aangesien dit volgens OpenAI hul sterkste model ten tyde van die studie was. Dit is ook een van die groottaalmodelle wat Afrikaans as deel van sy aanbod bied.
2 Steierwerk (“scaffolding”) is ’n onderrigtegniek waar gestruktureerde ondersteuning die ontwikkeling van die leerder/student bevorder deur komplekse konsepte in hanteerbare dele op te breek.
3 Aktiewe leer, gewortel in verskeie leerteorieë, vereis dat studente deur intellektuele ondersoek en metakognisie aktief deelneem aan betekenisvolle leerprosesse waarin hoërordedenke, probleemoplossing en die induktiewe ontdekking van konsepte sentraal staan (Le Hanie en Pottas, 2025).
Addendum A
Opdraginstruksies
Teksseleksie
a) Kies twee tot drie tekste wat binne die breë definisie van “tekste” val. Dit kan insluit, maar is nie beperk nie tot:
- Geskrewe tekste: artikels, opstelle, gedigte, kortverhale, romans, ens.
- Oudiotekste: podsendings, radio-uitsendings, toesprake, onderhoude, ens.
- Visuele tekste: skilderye, foto’s, advertensies, films, video’s, ens.
b) Die gekose tekste moet tematies verwant wees of op ’n betekenisvolle wyse met mekaar verband hou. Dit kan bv. ’n soortgelyke onderwerp deel, kontrasterende perspektiewe aanpak of verskillende voorstellings van ’n gemeenskaplike tema uitbeeld.
Inleiding
Gee ’n duidelike en bondige inleiding wat die geselekteerde tekste bekendstel en kortliks die betekenis en toepaslikheid daarvan vir u opstel uiteensit.
Vergelykende analise
a) Ontleed die geselekteerde tekste in hierdie afdeling krities. Oorweeg die volgende aspekte, soos van toepassing:
- Taalgebruik: Bespreek hoe die taal in elke teks gebruik word. Ontleed die styl, toon, diksie en retoriese middels wat deur die skeppers gebruik word.
- Inhoud en temas: Ondersoek die sentrale temas en onderwerp in elke teks. Vergelyk en kontrasteer die idees wat aangebied word.
- Mediumspesifieke elemente (geskrewe, visuele en/of oudio): Ondersoek hoe die medium die algehele boodskap en interpretasie beïnvloed.
- Gehoor en doel: Ondersoek die beoogde gehoor en doel van elke teks. Ontleed hoe dit die inhoud en aanbieding beïnvloed.
b) Gebruik spesifieke voorbeelde en bewyse uit die tekste om jou ontleding te ondersteun. Om toepaslike gedeeltes, reëls of tonele aan te haal, sal jou argument versterk.
Sintese
a) Identifiseer die ooreenkomste en verskille wat uit u analise na vore gekom het.
b) Besin oor die breër gevolge van hierdie bevindings. Kyk hoe die uiteenlopende taalgebruik en medium die kommunikasie van idees en betekenisse beïnvloed.
Gevolgtrekking
a) Som u hoofpunte en insigte uit die vergelykende analise op.
b) Sluit u teks af met ’n bondige samevatting wat die waarde van hierdie analise uiteensit.
Weergawes
U moet twee weergawes van u opstel indien. Die eerste weergawe is u rofwerkweergawe waarin u aanvanklike gedagtes en idees oor die onderwerp neerpen. Die tweede weergawe moet ’n hersiene en geredigeerde weergawe van u opstel wees waarin u die terugvoer van u dosent en/of medestudente bygewerk het.
Formaat
- Voorblad
- Inhoudsopgawe
- Inleiding
- Liggaam/teks (Gebruik asb. gepaste opskrifte en subopskrifte.)
- Samevatting
- Bronnelys
Rubriek
Klik op die tabel vir ’n groter weergawe.
| LitNet Akademies (ISSN 1995-5928) is geakkrediteer deur die Departement van Hoër Onderwys en Opleiding (DHET) en vorm deel van die Suid-Afrikaanse lys van goedgekeurde vaktydskrifte (South African list of approved journals). Hierdie artikel is portuurbeoordeel en kan kwalifiseer vir subsidie deur die Departement van Hoër Onderwys en Opleiding. |